Пример језика за рад са функцијама
У наставку ће бити представљен задатак какав се може наћи на испитним роковима. Циљ овог примера је да се покаже неколико кључних ствари које нису покривене у претходном разговору о синтаксним стаблима. То су:
- рад са кориснички дефинисаним (непримитивним) типовима
- истицање разлике између интерпретирања и формирања синтаксних стабала у акцијама у Bison-у (овде је она суптилнија него раније)
- решавање нових shift/reduce конфликата у граматикама
Ради лакшег праћења, кодови се могу наћи на GitHub репозиторијуму.
Задатак
Дат је програмски језик за рад са функцијама на следећи начин:
- на располагању су константе функције, идентичка функција,
sin,cosи све које се могу добити њиховом композицијом и основним аритметичким операцијама (изрази попутsin(x),cos(x),x,x + sin(x * x),cos(sin(x)) * cos(2 + x), приметимо даxпредставља идентичку функцију) - функције се могу чувати и доделити променљивама (наредбе попут
f = sin(x),g = f(x * x)) - могу да се рачунају вредности у тачки функција које су већ сачуване у променљивој (изрази попут
f[0.5]) - може да се рачуна извод функције (изрази попут
f') - функције и променљиве се исписују на стандардни излаз (наредбе попут
f,sin(g(x)),g'[-1]) - наредбе се завршавају новим редовима
Дакле, дат је програмски језика за рад са функцијама које можемо да компонујемо, рачунамо њихов извод, као и вредност у тачки, док имамо само два типа наредби—испис и доделу. Пример програма:
f = sin(x)
f'
f[1]
g = 1 + f(x*x)
g
g[0.5]
g'
g'[0.5]Задатак је да направимо:
- интерпретер за овај језик
- формирамо синтаксно стабло за њега које може да се исписује и интерпретира
Ово значи да је потребно да направимо два Bison пројекта, где ћемо у првом да вршимо интерпретацију, а у другом да формирамо синтаксно стабло.
Ово је тренутак где можете да покушате да урадите задатак самостално. Главна новина биће рад са непримитивним подацима, у овом случају, функцијама. Због тога је потребно направити одговарајући класни тип података који би их представљао.
Парсер
Као и свим задацима, почињемо од писања граматике језика и прављења парсера за језик који проверава само синтаксичку исправност улаза. Зато је потребно да направимо три фајла:
lexer.l(Flex фајл)parser.ypp(Bison фајл)Makefile
Граматика језика
Крећемо од граматике и језика које иницијално попуњавамо празним акцијама. Сегмент акција може да изледа овако:
parser.ypp
program
: niz_naredbi {}
;
niz_naredbi
: niz_naredbi naredba {}
| naredba {}
;
naredba
: ID '=' izraz '\n' {}
| izraz '\n' {}
| '\n' {}
;
izraz
: izraz '+' izraz {}
| izraz '-' izraz {}
| izraz '*' izraz {}
| izraz '/' izraz {}
| '-' izraz %prec UMINUS {}
| '(' izraz ')' {}
| izraz '\'' {}
| izraz '[' BROJ ']' {}
| izraz '(' izraz ')' {}
| SIN '(' izraz ')' {}
| COS '(' izraz ')' {}
| BROJ {}
| ID {}
| PROMENLJIVA {}
;Наредбе се не раздвајају ; већ новим редовима (симболом \n).
То за последицу има да ћемо у правилима за нетерминал naredba да додамо правило које одговара празној наредби.
Ово је потребно у случају да имамо више узастопних празних редова.
У правилима за izraz имамо правило izraz -> PROMENLJIVA које одговара симболу x у дефинисању функција (тј. идентичкој функцији).
Потребно је да га разликујемо јер је x у нашем језику резервирана реч.
Осим њега, поменимо да правило izraz -> izraz '(' izraz ')' одговара композицији функција, док су остала правила виђена у грађењу израза.
Када само написали правила граматике, потребно је да декларишемо све терминале (који нису једнокарактерски). Односно, у сегмент дефиниција додајемо:
parser.ypp
%token SIN COS PROMENLJIVA
%token ID
%token BROJМеђутим, нисмо готови—потребно је да разрешимо вишезначност наше граматике.
Shift/reduce конфликти
Ако бисмо покушали да преведемо овакав Bison фајл, добили бисмо наредну поруку.
parser.ypp: warning: 35 shift/reduce conflicts [-Wconflicts-sr]
parser.ypp: note: rerun with option '-Wcounterexamples' to generate conflict counterexamplesShift/reduce конфликти најчешће значе да имамо проблема са приоритетом и решаваћемо их тако што дефинишемо асоцијативност и приоритет токена. Од ових 35 конфликата сигурно су неки узроковани приоритетом основних аритметичких операција. Зато додајмо у сегмент дефиниција:
parser.ypp
%left '+' '-'
%left '*' '/'
%right UMINUSИ у правила граматике за унарни минус:
parser.ypp
izraz
...
| '-' izraz %prec UMINUS {}
...Поновним превођењем фајла parser.ypp добијамо нови испис.
parser.ypp: warning: 15 shift/reduce conflicts [-Wconflicts-sr]
parser.ypp: note: rerun with option '-Wcounterexamples' to generate conflict counterexamplesДакле, нисмо решили све конфликте.
У случају када нисмо сигурни где настају конфликти, односно, када не знамо којим токенима треба да доделимо приоритет, можемо да преведемо Bison фајл са опцијом -Wcounterexamples.
Излаз који добијамо при таквом покретању ће бити суштински низ контрапримера, од којих је сваки наредног облика:
parser.ypp: warning: shift/reduce conflict on token '\'' [-Wcounterexamples]
Example: izraz '+' izraz • '\''
Shift derivation
izraz
↳ 7: izraz '+' izraz
↳ 13: izraz • '\''
Reduce derivation
izraz
↳ 13: izraz '\''
↳ 7: izraz '+' izraz •Овде ће нам бити најзначајније прве две линије.
Прва нам говори на ком токену настаје конфликт, односно, ком то токену треба да доделимо приоритет да бисмо разрешили конфликт.
Док друга линија, након Example:, исписује контрапример који нам може помоћи за дубље разумевање проблема.
Наиме, овде видимо да конфликт настаје на токену '\'' тј. треба да доделимо приоритет оператору извода.
То заиста потврђује и генерисани пример на другој линији.
Парсер не зна како да тумачи реч izraz '+' izraz '\'': да ли као
(izraz '+' izraz) '\'',- или као
izraz '+' (izraz '\'')?
Зато треба да дефинишемо приоритет оператора за извод, тј. да додамо у сегмент дефиниција:
parser.ypp
%left '+' '-'
%left '*' '/'
%right UMINUS
%right '\''Међутим, ово није све јер Bison пријављује још конфликата. Неки од њих су следећи:
parser.ypp: warning: shift/reduce conflict on token '[' [-Wcounterexamples]
Example: izraz '+' izraz • '[' BROJ ']'parser.ypp: warning: shift/reduce conflict on token '(' [-Wcounterexamples]
Example: izraz '+' izraz • '(' izraz ')'Дакле, имамо проблем код оператора рачунања вредности функције у тачки и оператора композиције.
На пример, није јасно како израз izraz '+' izraz '[' BROJ ']' треба да се тумачи.
Да ли као:
(izraz '+' izraz) '[' BROJ ']',- или као
izraz '+' (izraz '[' BROJ ']')
Слично и код заграда () за композицију.
За разлику од претходних случајева, где је операторима одговарао само један токен (нпр. за сабирање, одузимање, извод и друге), овде оператор одређују два токена—одговарајућа отворена и затворена заграда. Из тог разлога, може бити нејасно како да одредимо приоритет у овом случају тј. ком од та два токена треба доделити приоритет?
Међутим, Bison нам даје одговор на то питање у првим редовима одговарајућих генерисаних контрапримера.
Конфликти настају на токенима '[' и '(', и потребно је и довољно само њима доделити приоритет.
Дакле, у ситуацијама сличним овим, потребно је доделити приоритет левој загради!
Коначно, треба да додамо у сегменту дефиниција следеће:
parser.ypp
%left '+' '-'
%left '*' '/'
%right UMINUS
%precedence '(' '['
%right '\''Подсетимо се да су дозвољене декларације асоцијативности:
%left- лева асоцијативност%right- десна асоцијативност%nonassoc- неасоцијативан оператор (грешка при извршавању ако се јави потреба за разрешавањем асоцијативности)%precedence- без навођења асоцијативности
Желимо да заграде буду међусобно истог приоритета, који је већи од приоритета аритметичких операција, али је мањи од извода.
Осим тога, не додељујемо им никакву асоцијативност, већ само користимо директиву %precedence да бисмо могли да их наведемо на одговарајућем месту и спецификујемо им приоритет на тај начин (није неопходно користити %precedence овде, може се користити и нпр. %left али је дато ради комплетности).
Објашњење зашто је довољно доделити приоритете левим заградама, као и шта су заправо shift/reduce конфликти, се може наћи у додатку. Оно може бити од користи за разрешавање конфликата у случајевима који нису покривени овде, али и за дубље разумевање рада парсера у позадини.
Лексер
Сада је могуће написати и лексер јер знамо који су нам токени потребни.
lexer.l
%option noyywrap
%{
#include <iostream>
#include <cstdlib>
#include "parser.tab.hpp"
%}
PRIR_BROJ 0|[1-9][0-9]*
REAL_BROJ [+-]?{PRIR_BROJ}(\.{PRIR_BROJ}([eE][+-]{PRIR_BROJ})?)?
IDENTIFIKATOR [_a-zA-Z][_a-zA-Z0-9]*
%%
x {
return PROMENLJIVA;
}
sin {
return SIN;
}
cos {
return COS;
}
{IDENTIFIKATOR} {
return ID;
}
{REAL_BROJ} {
return BROJ;
}
[+\-*/()\[\]='\n] {
return *yytext;
}
[ \t] {
}
. {
std::cerr << "leksicka greska: " << yytext << std::endl;
exit(EXIT_FAILURE);
}
%%Приметимо да сада симбол за нови ред \n не игноришемо јер нам је он сепаратор наредби.
Повезивање
Направимо још и Make фајл зарад лакшег превођења. Он може да изледа овако:
Makefile
CC = g++
CFLAGS = -Wall -Wextra
parser: lex.yy.o parser.tab.o
$(CC) $(CFLAGS) $^ -o $@
lex.yy.o: lex.yy.c
$(CC) $(CFLAGS) -c $< -o $@
lex.yy.c: lexer.l parser.tab.hpp
flex --nounput $<
parser.tab.o: parser.tab.cpp parser.tab.hpp
$(CC) $(CFLAGS) -c $< -o $@
parser.tab.cpp parser.tab.hpp: parser.ypp
bison --header $<
.PHONY: clean
clean:
rm -f *.o parser lex.yy.c parser.tab.*Превођењем и покретањем добијамо парсер за наш језик. Оно што је важно је да ћемо у оба наредна дела тј. и за интерпретер, и за синтаксно стабло, да користимо исту граматику. Дакле, само ће се разликовати акције у правилима граматике.
Интерпретација
Први део задатка је да направимо интерпретер за овај језик. То значи да треба да попунимо постојећа правила граматике одговарајућим акцијама које би извршавале наредбе програма.
Приметимо да наш програм треба да ради са функцијама—може да их чува, извршава основне аритметичке операције над њима, исписује их, компонује, рачуна извод и вредност у тачки. Дакле, радимо са сложеним типом података и пожељно је да направимо посебну класу која би представљала тај тип, док би сву логику ставили у одговарајуће методе те класе.
Зато правимо нову класу Funkcija и два нова фајла funkcija.hpp и funkcija.cpp у којима ћемо да имплементирамо ову класу.
Међутим, једна класа нам не може бити довољна да обухватимо целокупну логику функција које нам се појављују. Наиме, посматрајмо наредни програм:
f = sin(x)
f'
g = cos(x)
g'
h = f + g(f(x))
h'Овде је функција f синусна функција, g косинусна, док је h добијена њиховим комбиновањем.
Уколико бисмо имали само једну класу чијег типа би биле све ове функције, поставља се неколико питања.
Како ћемо чувати функцију h која није елементарна функција?
Како да рачунамо изводе свих поменутих функција које су очигледно доста другачије?
Решење које ћемо овде применити је да функције представљамо дрволиком структуром чији ће чворови бити елементарне функције (константна, идентичка, sin, cos, негација, сабирање, одузимање, множење и дељење) за које ћемо правити засебне класе.
На пример, функција f која је једнака sin(x) ће бити:
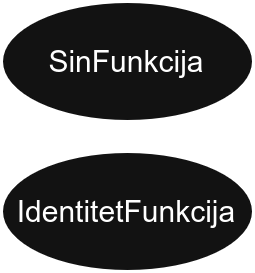
Слично, функција g = cos(x) ће бити:
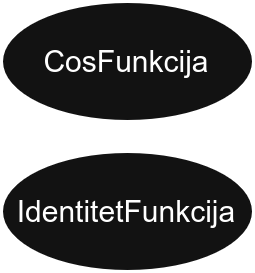
Док ће функција h која је једнака sin(x) + cos(sin(x)), бити чувана на следећи начин:
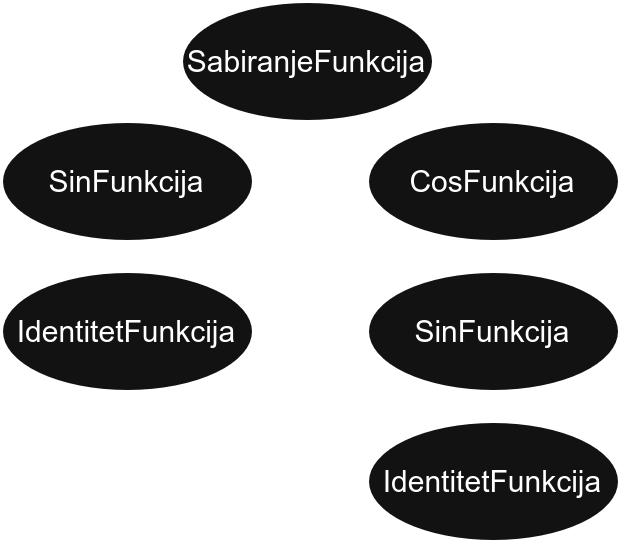
Сваки чвор представља неку елементарну функцију, док деца представљају аргументе те функције.
Зато неки чворови имају два детета (попут SabiranjeFunkcija), неки једно (попут SinFunkcija), а неки ниједно (као што је IdentitetFunkcija).
Да бисмо ово имплементирали, биће нам потребна апстрактна класа коју ће све функције наслеђивати, и то ће бити класа Funkcija.
Остале класе ће поштовати следећу хијерархију:
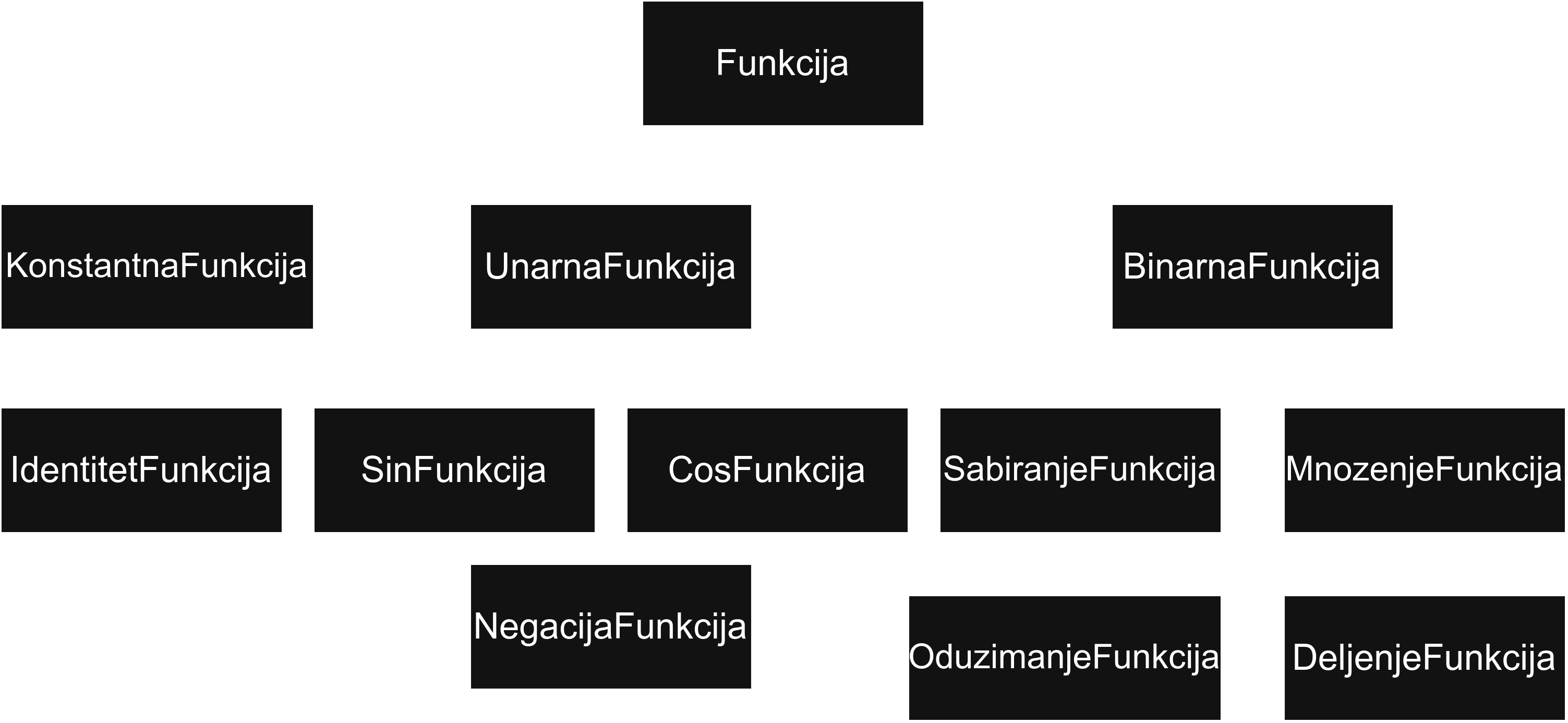
Приметимо да уводимо помоћне апрстрактне класе UnarnaFunkcija и BinarnaFunkcija које ће наслеђивати све функције са једним, односно два детета.
На тај начин олакшавамо мало посао око писања свих класа, јер ће се сва заједничка логика за нпр. класе које представљају унарне функције налазити у тој апстрактној међукласи, чиме смањујемо дупликацију кода.
Напомена: Приметимо да ова хијерархија доста подсећа на хијерархију коју смо користили код синтаксних стабала. Међутим, ове класе нису класе које ћемо користити за чворове синтаксног стабла! Касније ће бити детаљније објашњење о разлици, али за сада треба да посматрамо да овде правимо само интерпретер који је потпуно независан од другог дела задатка (формирања синтаксног стабла). Из тог разлога имена свих класа имају суфикс
Funkcija.
Ипак, пожељно је упознати се са хијерархијом синтаксног стабла из претходних лекција јер ће се даље користити имплементационе технике и идеје које су тамо покривене.
Класа Funkcija
Класа Funkcija је на врху хијерархије и представља апстрактну класу које ће све остале наслеђивати.
Она треба да декларише и све методе које једна функција у нашем програму треба да имплементира.
То су методе за испис функције, рачунање вредности функције у тачки, за извод и за композицију са другом функцијом.
Поред њих, како је ово апстрактна класа коју ће наслеђивати класе које чувају показиваче (правимо дрволику структуру), то ће бити потребно да декларишемо и виртуелни дестуктор у овој класи, али и методу kloniraj која ће служити за прављење копије функције.
Декларација може да изгледа овако:
funkcija.hpp
class Funkcija {
public:
virtual ~Funkcija();
virtual double izracunaj(double vrednost) const = 0;
virtual void ispisi(std::ostream &os) const = 0;
virtual Funkcija *izvod() const = 0;
virtual Funkcija *komponuj(Funkcija *funkcija) const = 0;
virtual Funkcija *kloniraj() const = 0;
};
std::ostream &operator<<(std::ostream &os, const Funkcija &funkcija);Метода izracunaj прима реалан број и враћа реалан број који представља вредност функције у тој тачки.
Метода ispisi исписује функцију на std::ostream што користимо за преоптерећивање оператора <<.
Методе izvod и komponuj су замишљене да не мењају објекат функције над којим се позивају већ да направе нов објекат тј. нову функцију која је једнака изводу, односно нову функцију која одговара композицији, те зато враћају Funkcija * и обележене су кључном речи const.
Што се тиче funkcija.cpp фајла, ту је потребно само дефинисати деструктор (макар он био и празан, јер свака наткласа мора имати деструктор) и преоптеретити оператор <<.
funkcija.cpp
Funkcija::~Funkcija() {}
std::ostream &operator<<(std::ostream &os, const Funkcija &funkcija) {
funkcija.ispisi(os);
return os;
}Класа KonstantnaFunkcija
Ова функција треба да чува један реалан број и зато, поред метода које наслеђује, треба још да имплементира одговарајући конструктор. Како чува само један податак који је примитивног типа, не треба да предефинише деструктор.
funkcija.hpp
class KonstantnaFunkcija : public Funkcija {
public:
KonstantnaFunkcija(double vrednost);
// metode iz natklase
double izracunaj(double vrednost) const override;
void ispisi(std::ostream &os) const override;
Funkcija *izvod() const override;
Funkcija *komponuj(Funkcija *funkcija) const override;
Funkcija *kloniraj() const override;
private:
double m_vrednost;
};Одговарајуће имплементације могу да буду попут наредних:
funkcija.cpp
KonstantnaFunkcija::KonstantnaFunkcija(double vrednost)
: m_vrednost(vrednost) {}
double KonstantnaFunkcija::izracunaj(double vrednost) const {
return m_vrednost;
}
void KonstantnaFunkcija::ispisi(std::ostream &os) const {
os << m_vrednost;
}
Funkcija *KonstantnaFunkcija::izvod() const {
return new KonstantnaFunkcija(0);
}
Funkcija *KonstantnaFunkcija::komponuj(Funkcija *funkcija) const {
return new KonstantnaFunkcija(*this);
}
Funkcija *KonstantnaFunkcija::kloniraj() const {
return new KonstantnaFunkcija(*this);
}Као што смо и напоменули, методе izvod и komponuj не мењају објекат над којим се позивају, већ креирају нови.
Из тог разлога метода за извод враћа нову константну функцију која представља нулу, а композиција константне функције са било којом функцијом враћа баш ту константну функцију.
У овим методама позивамо подразумевани конструктор копије који нам је овде довољан јер класа чува само примитиван тип.
Класа IdentitetFunkcija
Ова класа представља идентичку функцију (коју у програму означавамо са x).
Она не треба да чува никакав додатни податак, већ само да имплементира методе наткласе.
funkcija.hpp
class IdentitetFunkcija : public Funkcija {
public:
// metode iz natklase
double izracunaj(double vrednost) const override;
void ispisi(std::ostream &os) const override;
Funkcija *izvod() const override;
Funkcija *komponuj(Funkcija *funkcija) const override;
Funkcija *kloniraj() const override;
};funkcija.cpp
double IdentitetFunkcija::izracunaj(double vrednost) const {
return vrednost;
}
void IdentitetFunkcija::ispisi(std::ostream &os) const {
os << "x";
}
Funkcija *IdentitetFunkcija::izvod() const {
return new KonstantnaFunkcija(1);
}
Funkcija *IdentitetFunkcija::komponuj(Funkcija *funkcija) const {
return funkcija->kloniraj(); // moramo da pravimo kopiju!
}
Funkcija *IdentitetFunkcija::kloniraj() const {
return new IdentitetFunkcija(*this);
}Овде је важно обратити пажњу да метода komponuj не може само да прослеђује аргумент funkcija.
Тј. не може само да буде
Funkcija *IdentitetFunkcija::komponuj(Funkcija *funkcija) const {
return funkcija;
}већ је неопходно да прави копију аргумента.
Разлог за то је што метода komponuj ради тако што рекурзивно обилази функцију и на листове надовезује функцију аргумент.
Зато, уколико постоји више листова, желимо сваки пут да правимо нову копију функције.
Погледајмо на примеру.
Нека је дата функција f = sin(x) + 2 * cos(x).
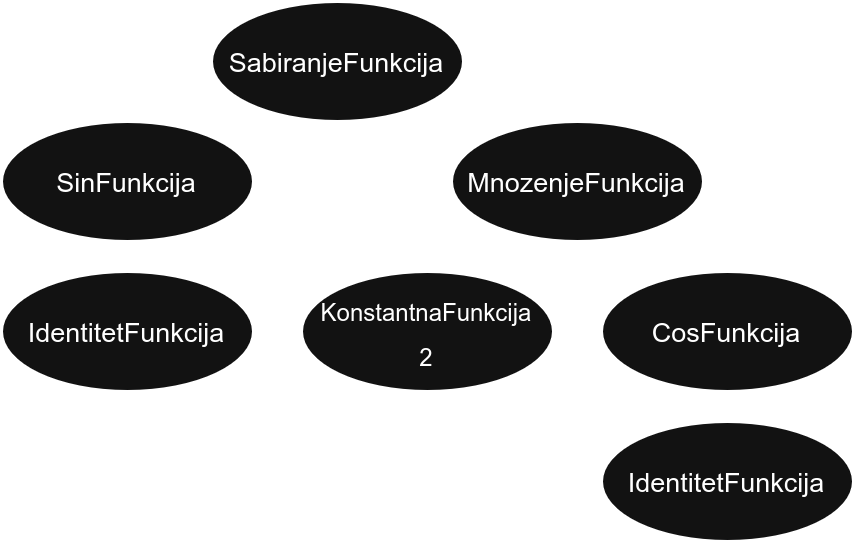
И желимо да је компонујемо са функцијом g = cos(x).
Њихова композиција f(g(x)) = sin(cos(x)) + 2 * cos(cos(x)) ће бити нова функција која изгледа овако:
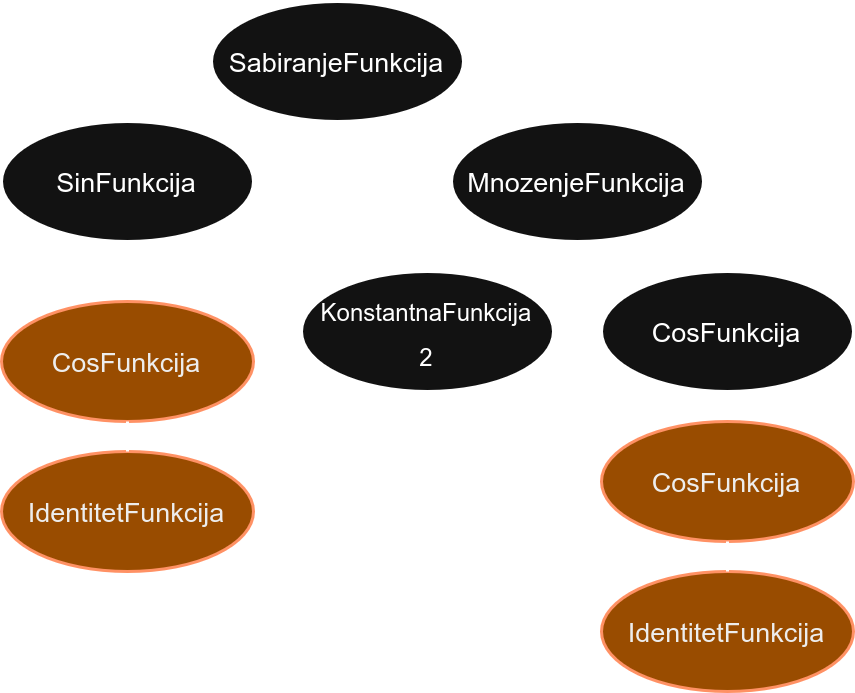
Позив методе f->komponuj(g) ће покренути позив методе komponuj над свим чворовима стабла функције f и прослеђиваће се све до листова где ће се (у зависноти од типа листа) надовезати функција g.
У овом примеру, листови функције f су два чвора типа IdentitetFunkcija и један KonstantnaFunkcija.
Као што смо видели, константна функција не треба ништа да промени, док идентична функција треба да постави функцију g уместо себе.
Уколико бисмо у методи IdentitetFunkcija::komponuj само враћали аргумент, добили бисмо следеће стабло:
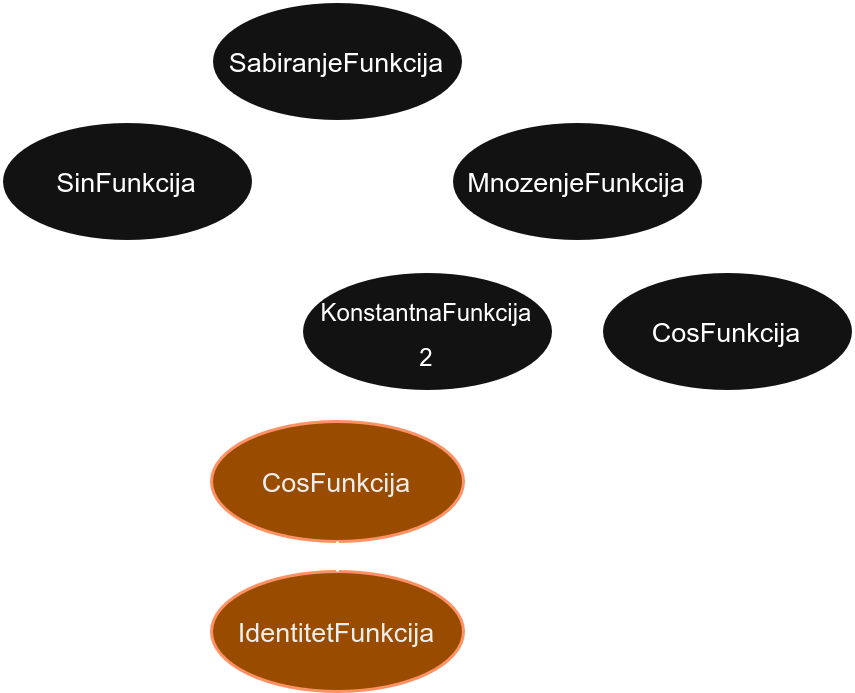
Дакле, не бисмо правили посебне копије за сваки лист, већ бисмо само превезали показиваче. То није жељено понашање у овом случају (нпр. направиће проблем приликом позива деструктора), те је неопходно да правимо копију у имплементацији методе тј. треба да стоји
Funkcija *IdentitetFunkcija::komponuj(Funkcija *funkcija) const {
return funkcija->kloniraj();
}Класа UnarnaFunkcija и њене поткласе
Ово је међукласа која обједињује заједничке делове свих класа које представљају функције са једним аргументом.
Биће готово идентична класи UnarniCvor из лекције о синтаксним стаблима.
Чуваће један показивач на функцију који представља аргумент. Чим чувамо показиваче на динамички алоцирану меморију, потребно је да предефинишемо деструктор и конструктор копије (слично као раније, ни овде нећемо да предефинишемо оператор доделе).
funkcija.hpp
class UnarnaFunkcija : public Funkcija {
public:
UnarnaFunkcija(Funkcija *funkcija);
UnarnaFunkcija(const UnarnaFunkcija &druga);
~UnarnaFunkcija();
// metode iz natklase
virtual double izracunaj(double vrednost) const = 0;
virtual void ispisi(std::ostream &os) const = 0;
virtual Funkcija *izvod() const = 0;
virtual Funkcija *komponuj(Funkcija *funkcija) const = 0;
virtual Funkcija *kloniraj() const = 0;
protected:
Funkcija *m_funkcija;
};funkcija.cpp
UnarnaFunkcija::UnarnaFunkcija(Funkcija *funkcija)
: m_funkcija(funkcija) {}
UnarnaFunkcija::UnarnaFunkcija(const UnarnaFunkcija &druga) {
m_funkcija = druga.m_funkcija->kloniraj();
}
UnarnaFunkcija::~UnarnaFunkcija() {
delete m_funkcija;
}У наставку су дате класе које је наслеђују: NegacijaFunkcija, SinFunkcija и CosFunkcija.
Ниједна од њих неће имати нова поља, али ће бити неопходно да свака дефинише конструктор истог потписа као конструктор из наткласе UnarnaFunkcija.
Поред тога, неће бити потребно предефинисати ни деструктор, ни конструктор копије јер ће се наследити одговарајући из наткласе.
Класа
NegacijaFunkcija
funkcija.hpp
class NegacijaFunkcija : public UnarnaFunkcija {
public:
NegacijaFunkcija(Funkcija *funkcija);
// metode iz natklase
double izracunaj(double vrednost) const override;
void ispisi(std::ostream &os) const override;
Funkcija *izvod() const override;
Funkcija *komponuj(Funkcija *funkcija) const override;
Funkcija *kloniraj() const override;
};funkcija.cpp
NegacijaFunkcija::NegacijaFunkcija(Funkcija *funkcija)
: UnarnaFunkcija(funkcija) {}
double NegacijaFunkcija::izracunaj(double vrednost) const {
return - m_funkcija->izracunaj(vrednost);
}
void NegacijaFunkcija::ispisi(std::ostream &os) const {
os << "- (" << *m_funkcija << ")";
}
Funkcija *NegacijaFunkcija::izvod() const {
return new NegacijaFunkcija(m_funkcija->izvod());
}
Funkcija *NegacijaFunkcija::komponuj(Funkcija *funkcija) const {
return new NegacijaFunkcija(m_funkcija->komponuj(funkcija));
}
Funkcija *NegacijaFunkcija::kloniraj() const {
return new NegacijaFunkcija(*this);
}Приметимо како се у методи komponuj прво врши композиција подфункције, а онда се прави нова функција.
То се уклапа уз поменути опис да се композиција извршава тако што обилазимо функцију до листова, а затим у повратку формирамо нову коју враћамо као резултат.
Класа
SinFunkcija
funkcija.hpp
class SinFunkcija : public UnarnaFunkcija {
public:
SinFunkcija(Funkcija *funkcija);
// metode iz natklase
double izracunaj(double vrednost) const override;
void ispisi(std::ostream &os) const override;
Funkcija *izvod() const override;
Funkcija *komponuj(Funkcija *funkcija) const override;
Funkcija *kloniraj() const override;
};funkcija.cpp
SinFunkcija::SinFunkcija(Funkcija *funkcija)
: UnarnaFunkcija(funkcija) {}
double SinFunkcija::izracunaj(double vrednost) const {
return sin(m_funkcija->izracunaj(vrednost));
}
void SinFunkcija::ispisi(std::ostream &os) const {
os << "sin(" << *m_funkcija << ")";
}
Funkcija *SinFunkcija::izvod() const {
return new MnozenjeFunkcija(
new CosFunkcija(m_funkcija->kloniraj()),
m_funkcija->izvod()
);
}
Funkcija *SinFunkcija::komponuj(Funkcija *funkcija) const {
return new SinFunkcija(m_funkcija->komponuj(funkcija));
}
Funkcija *SinFunkcija::kloniraj() const {
return new SinFunkcija(*this);
}Овде треба обратити пажњу на методу izvod.
Наиме, важи следеће
(sin(m_funkcija))' = cos(m_funkcija) * m_funkcija'Што је и записано у имплементацији ове методе.
Међутим, приметимо да правимо копију функције m_funkcija.
Разлог за то је што метода за извод треба да врати потпуно нови објекат, па желимо да копирамо све постојеће објекте, а не само да превежемо показиваче ка њима (сличан разлог као код методе komponuj у IdentitetFunkcija).
Класа
CosFunkcija
funkcija.hpp
class CosFunkcija : public UnarnaFunkcija {
public:
CosFunkcija(Funkcija *funkcija);
// metode iz natklase
double izracunaj(double vrednost) const override;
void ispisi(std::ostream &os) const override;
Funkcija *izvod() const override;
Funkcija *komponuj(Funkcija *funkcija) const override;
Funkcija *kloniraj() const override;
};funkcija.cpp
CosFunkcija::CosFunkcija(Funkcija *funkcija)
: UnarnaFunkcija(funkcija) {}
double CosFunkcija::izracunaj(double vrednost) const {
return cos(m_funkcija->izracunaj(vrednost));
}
void CosFunkcija::ispisi(std::ostream &os) const {
os << "cos(" << *m_funkcija << ")";
}
Funkcija *CosFunkcija::izvod() const {
return new NegacijaFunkcija(
new MnozenjeFunkcija(
new SinFunkcija(m_funkcija->kloniraj()),
m_funkcija->izvod()
)
);
}
Funkcija *CosFunkcija::komponuj(Funkcija *funkcija) const {
return new CosFunkcija(m_funkcija->komponuj(funkcija));
}
Funkcija *CosFunkcija::kloniraj() const {
return new CosFunkcija(*this);
}Аналогно синусног функцији, овде за извод имамо наредно правило:
(cos(m_funkcija))' = - sin(m_funkcija) * m_funkcija'Класа BinarnaFunkcija и њене поткласе
Ово је апстрактна класа која треба да представља функције са два аргумента.
Њена структура је слична структури класе UnarnaFunkcija са главном разликом да ће чувати два показивача уместо једног.
Због чувања показивача, потребно је да предефинишемо подразумевани деструктор и конструктор копије.
funkcija.hpp
class BinarnaFunkcija : public Funkcija {
public:
BinarnaFunkcija(Funkcija *leva, Funkcija *desna);
BinarnaFunkcija(const BinarnaFunkcija &druga);
~BinarnaFunkcija();
// metode iz natklase
virtual double izracunaj(double vrednost) const = 0;
virtual void ispisi(std::ostream &os) const = 0;
virtual Funkcija *izvod() const = 0;
virtual Funkcija *komponuj(Funkcija *funkcija) const = 0;
virtual Funkcija *kloniraj() const = 0;
protected:
Funkcija *m_leva, *m_desna;
};funkcija.cpp
BinarnaFunkcija::BinarnaFunkcija(Funkcija *leva, Funkcija *desna)
: m_leva(leva), m_desna(desna) {}
BinarnaFunkcija::BinarnaFunkcija(const BinarnaFunkcija &druga) {
m_leva = druga.m_leva->kloniraj();
m_desna = druga.m_desna->kloniraj();
}
BinarnaFunkcija::~BinarnaFunkcija() {
delete m_leva;
delete m_desna;
}Дакле, ово је апстрактна класа и све преостале методе треба да дефинишу класе које је наслеђују.
У овом случају, то су класе SabiranjeFunkcija, OduzimanjeFunkcija, MnozenjeFunkcija и DeljenjeFunkcija.
Опет, зато што смо предефинисали деструктор и конструктор копије у наткласи, за ове класе биће довољно само да дефинишемо одговарајући конструктор. Имплементације су у наставку.
Класа
SabiranjeFunkcija
funkcija.hpp
class SabiranjeFunkcija : public BinarnaFunkcija {
public:
SabiranjeFunkcija(Funkcija *leva, Funkcija *desna);
// metode iz natklase
double izracunaj(double vrednost) const override;
void ispisi(std::ostream &os) const override;
Funkcija *izvod() const override;
Funkcija *komponuj(Funkcija *funkcija) const override;
Funkcija *kloniraj() const override;
};funkcija.cpp
SabiranjeFunkcija::SabiranjeFunkcija(Funkcija *leva, Funkcija *desna)
: BinarnaFunkcija(leva, desna) {}
double SabiranjeFunkcija::izracunaj(double vrednost) const {
return m_leva->izracunaj(vrednost) + m_desna->izracunaj(vrednost);
}
void SabiranjeFunkcija::ispisi(std::ostream &os) const {
os << "(" << *m_leva << ") + (" << *m_desna << ")";
}
Funkcija *SabiranjeFunkcija::izvod() const {
return new SabiranjeFunkcija(
m_leva->izvod(),
m_desna->izvod()
);
}
Funkcija *SabiranjeFunkcija::komponuj(Funkcija *funkcija) const {
return new SabiranjeFunkcija(
m_leva->komponuj(funkcija),
m_desna->komponuj(funkcija)
);
}
Funkcija *SabiranjeFunkcija::kloniraj() const {
return new SabiranjeFunkcija(*this);
}
Класа
OduzimanjeFunkcija
funkcija.hpp
class OduzimanjeFunkcija : public BinarnaFunkcija {
public:
OduzimanjeFunkcija(Funkcija *leva, Funkcija *desna);
// metode iz natklase
double izracunaj(double vrednost) const override;
void ispisi(std::ostream &os) const override;
Funkcija *izvod() const override;
Funkcija *komponuj(Funkcija *funkcija) const override;
Funkcija *kloniraj() const override;
};funkcija.cpp
OduzimanjeFunkcija::OduzimanjeFunkcija(Funkcija *leva, Funkcija *desna)
: BinarnaFunkcija(leva, desna) {}
double OduzimanjeFunkcija::izracunaj(double vrednost) const {
return m_leva->izracunaj(vrednost) - m_desna->izracunaj(vrednost);
}
void OduzimanjeFunkcija::ispisi(std::ostream &os) const {
os << "(" << *m_leva << ") - (" << *m_desna << ")";
}
Funkcija *OduzimanjeFunkcija::izvod() const {
return new OduzimanjeFunkcija(
m_leva->izvod(),
m_desna->izvod()
);
}
Funkcija *OduzimanjeFunkcija::komponuj(Funkcija *funkcija) const {
return new OduzimanjeFunkcija(
m_leva->komponuj(funkcija),
m_desna->komponuj(funkcija)
);
}
Funkcija *OduzimanjeFunkcija::kloniraj() const {
return new OduzimanjeFunkcija(*this);
}
Класа
MnozenjeFunkcija
funkcija.hpp
class MnozenjeFunkcija : public BinarnaFunkcija {
public:
MnozenjeFunkcija(Funkcija *leva, Funkcija *desna);
// metode iz natklase
double izracunaj(double vrednost) const override;
void ispisi(std::ostream &os) const override;
Funkcija *izvod() const override;
Funkcija *komponuj(Funkcija *funkcija) const override;
Funkcija *kloniraj() const override;
};funkcija.cpp
MnozenjeFunkcija::MnozenjeFunkcija(Funkcija *leva, Funkcija *desna)
: BinarnaFunkcija(leva, desna) {}
double MnozenjeFunkcija::izracunaj(double vrednost) const {
return m_leva->izracunaj(vrednost) * m_desna->izracunaj(vrednost);
}
void MnozenjeFunkcija::ispisi(std::ostream &os) const {
os << "(" << *m_leva << ") * (" << *m_desna << ")";
}
Funkcija *MnozenjeFunkcija::izvod() const {
return new SabiranjeFunkcija(
new MnozenjeFunkcija(
m_leva->izvod(),
m_desna->kloniraj()
),
new MnozenjeFunkcija(
m_leva->kloniraj(),
m_desna->izvod()
)
);
}
Funkcija *MnozenjeFunkcija::komponuj(Funkcija *funkcija) const {
return new MnozenjeFunkcija(
m_leva->komponuj(funkcija),
m_desna->komponuj(funkcija)
);
}
Funkcija *MnozenjeFunkcija::kloniraj() const {
return new MnozenjeFunkcija(*this);
}Овде је једина новина рачунање извода. Наиме, важи
(f * g)' = f' * g + f * g'при чему је важно да водимо рачуна (као и у претходним сличним ситуацијама) да правимо копије одговарајућих објеката.
Класа
DeljenjeFunkcija
Овде за извод користимо једнакост
(f / g)' = (f' * g - f * g') / (g * g)funkcija.hpp
class DeljenjeFunkcija : public BinarnaFunkcija {
public:
DeljenjeFunkcija(Funkcija *leva, Funkcija *desna);
// metode iz natklase
double izracunaj(double vrednost) const override;
void ispisi(std::ostream &os) const override;
Funkcija *izvod() const override;
Funkcija *komponuj(Funkcija *funkcija) const override;
Funkcija *kloniraj() const override;
};funkcija.cpp
DeljenjeFunkcija::DeljenjeFunkcija(Funkcija *leva, Funkcija *desna)
: BinarnaFunkcija(leva, desna) {}
double DeljenjeFunkcija::izracunaj(double vrednost) const {
return m_leva->izracunaj(vrednost) / m_desna->izracunaj(vrednost);
}
void DeljenjeFunkcija::ispisi(std::ostream &os) const {
os << "(" << *m_leva << ") / (" << *m_desna << ")";
}
Funkcija *DeljenjeFunkcija::izvod() const {
return new DeljenjeFunkcija(
new OduzimanjeFunkcija(
new MnozenjeFunkcija(
m_leva->izvod(),
m_desna->kloniraj()
),
new MnozenjeFunkcija(
m_leva->kloniraj(),
m_desna->izvod()
)
),
new MnozenjeFunkcija(
m_desna->kloniraj(),
m_desna->kloniraj()
)
);
}
Funkcija *DeljenjeFunkcija::komponuj(Funkcija *funkcija) const {
return new DeljenjeFunkcija(
m_leva->komponuj(funkcija),
m_desna->komponuj(funkcija)
);
}
Funkcija *DeljenjeFunkcija::kloniraj() const {
return new DeljenjeFunkcija(*this);
}Акције у Bison-у
Да бисмо коначно извршили интерпретацију нашег програма, потребно је да попунимо акције граматике у Bison фајлу.
Како у нашем програмском језику дозвољавамо употребу променљивих, за извршавање ће бити потребно да обезбедимо механизам чувања променљивих и њихових вредности.
То смо до сада радили тако што смо чували једну глобалну мапу типа std::map<std::string, tip_izraza> где је tip_izraza тип променљивих са којим радимо у програму (нпр. double ако су променљиве реални бројеви).
То ћемо и овде урадити, али ћемо, налик претходним лекцијама, направити посебну омотач-класу око мапе таквог типа и сву логику ћемо енкапсулирати унутар ње.
Зато правимо класу TabelaSimbola за те потребе.
Поред тога, класа
TabelaSimbolaће нам бити потребна за други део задатка—формирање синтаксног стабла.
Класа
TabelaSimbola
Ова класа је суштински иста као и она из лекције о синтаксним стаблима, међутим, постоји једна битна разлика.
Овде су нам изрази сложеног типа Funkcija и променљиве треба да чувају вредности тог типа.
Када је потребно да чувамо променљиве сложеног типа увек ћемо чувати показиваче на њих.
У овом случају, то ће значити да ће мапа бити типа:
std::map<std::string, Funkcija *>Поново, када год видимо показиваче (који показују на динамички алоцирану меморију), треба да размишљамо о њиховом ослобађању. Зато ће нам овде бити потребно да предефинишемо деструктор (конструктор копије и оператор доделе нам неће бити потребни).
tabela_simbola.hpp
#ifndef TABELA_SIMBOLA_HPP
#define TABELA_SIMBOLA_HPP
#include <map>
#include "funkcija.hpp"
class TabelaSimbola {
public:
~TabelaSimbola();
void dodeli_vrednost(const std::string &promenljiva, Funkcija *vrednost);
Funkcija *vrednost_promenljive(const std::string &promenljiva) const;
private:
std::map<std::string, Funkcija *> m_tabela;
};
#endiftabela_simbola.cpp
#include "tabela_simbola.hpp"
TabelaSimbola::~TabelaSimbola() {
for (auto &p : m_tabela) {
delete p.second;
}
}
void TabelaSimbola::dodeli_vrednost(const std::string &promenljiva, Funkcija *vrednost) {
auto it = m_tabela.find(promenljiva);
if (it != m_tabela.end()) {
delete it->second;
}
m_tabela[promenljiva] = vrednost;
}
Funkcija *TabelaSimbola::vrednost_promenljive(const std::string &promenjliva) const {
auto it = m_tabela.find(promenjliva);
if (it == m_tabela.end()) {
std::cerr << "promenljiva " << promenjliva << " nije definisana" << std::endl;
exit(EXIT_FAILURE);
}
return it->second;
}Још једном напоменимо да у имплементацији методе vrednost_promenljive не можемо да урадимо само:
return m_tabela[promenljiva]; // greska!јер она константна метода, већ морамо да користимо методу find.
Већ сада можемо да дефинишемо једну глобалну променљиву овог типа у parser.ypp фајлу коју ћемо користити у акцијама за рад са променљивама.
Зато додајемо у сегменту дефиниција, у делу за C++ код следеће:
parser.ypp
%{
#include "tabela_simbola.hpp"
// ...
TabelaSimbola tabela_simbola;
%}Акције
Сада можемо да попуњавамо правила граматике одговарајућим акцијама.
Главни део биће како интерпретирати правила за нетерминал izraz тј. како формирати изразе током парсирања.
То радимо слично као и до сада (није лоше подсетити се како се извршавају акције у позадини).
Акције за основне аритметичке операције функција су следеће:
parser.ypp
izraz
: izraz '+' izraz {
$$ = new SabiranjeFunkcija($1, $3);
}
| izraz '-' izraz {
$$ = new OduzimanjeFunkcija($1, $3);
}
| izraz '*' izraz {
$$ = new MnozenjeFunkcija($1, $3);
}
| izraz '/' izraz {
$$ = new DeljenjeFunkcija($1, $3);
}
| '-' izraz %prec UMINUS {
$$ = new NegacijaFunkcija($2);
}
| '(' izraz ')' {
$$ = $2;
}
| BROJ {
$$ = new KonstantnaFunkcija($1);
}Дакле, приликом парсирања израза само креирамо одговарајуће функције.
Ово значи да желимо да нам нетерминал izraz буде типа Funkcija * и то морамо да наведемо парсеру.
Поред тога, биће потребно да наведемо да је токен BROJ типа double, и токен ID показивач на ниску.
Зато додајемо у сегмент дефиниција:
parser.ypp
%union {
double realan_broj;
std::string *niska;
Funkcija *funkcija;
}
%token SIN COS PROMENLJIVA
%token<niska> ID
%token<realan_broj> BROJ
%type<funkcija> izrazНе заборавимо да додамо лексеру одговарајуће акције приликом препознавања бројева, односно идентификатора.
Прецизније, треба да сачува вредности у одговарајуће поље променљиве yylval.
lexer.l
{IDENTIFIKATOR} {
yylval.niska = new std::string(yytext);
return ID;
}
{REAL_BROJ} {
yylval.realan_broj = atof(yytext);
return BROJ;
}Сада можемо да наставимо са попуњавањем преосталих правила за изразе.
parser.ypp
izraz
: ID {
$$ = tabela_simbola.vrednost_promenljive(*$1)->kloniraj();
delete $1;
}Дакле, када се приликом парсирања наиђе на идентификатор, оно што интерпретер треба да уради је да врати вредности променљиве коју тај идентификатор представља.
Зато користимо претходно дефинисану променљиву tabela_simbola и над њом позивамо методу која враћа вредност променљиве.
Међутим, овде је важно да враћени објекат копирамо (тј. позовемо методу kloniraj) јер не радимо са примитивним типовима, већ табела симбола чува показиваче на наш дефинисани тип.
У супротном, при сваком парсирању конкретног идентификатора бисмо враћали увек исти објекат, што није семантика коју желимо (такво притко копирање ће нпр. изазвати проблем вишеструког ослобађања меморије).
Остају наредне акције за попунавање:
parser.ypp
izraz
: izraz '\'' {
$$ = $1->izvod();
delete $1;
}
| izraz '[' BROJ ']' {
$$ = new KonstantnaFunkcija($1->izracunaj($3));
delete $1;
}
| izraz '(' izraz ')' {
$$ = $1->komponuj($3);
delete $1;
delete $3;
}
| SIN '(' izraz ')' {
$$ = new SinFunkcija($3);
}
| COS '(' izraz ')' {
$$ = new CosFunkcija($3);
}
| PROMENLJIVA {
$$ = new IdentitetFunkcija();
}Ове акције представљају једноставне позиве одговарајућих метода које смо већ имплементирали. Међутим, њихова тежина се огледа у правилном управљању меморијом, за које је потребно да разумемо шта нам тачно раде методе које позивамо.
На пример, погледајмо акцију за извод.
parser.ypp
izraz
: izraz '\'' {
$$ = $1->izvod();
delete $1;
}Приликом дизајна класе Funkcija смо изабрали да метода izvod креира нови објекат типа Funkcija и враћа показивач на њега.
То значи да ће након прве доделе у акцији, показивач $1 показивати на меморију која нам више није потребна, те је одмах ослобађамо.
Слично и у осталим правилима водимо рачуна шта нам више није потребно и позивамо деструкторе над тим објектима.
Када смо формирали изразе, остају још наредбе.
parser.ypp
naredba
: ID '=' izraz '\n' {
tabela_simbola.dodeli_vrednost(*$1, $3);
delete $1;
}
| izraz '\n' {
std::cout << *$1 << std::endl;
delete $1;
}
| '\n' {}
;Чиме комплетирамо наш парсер.
Сада остаје још да га преведемо и тестирамо.
За то је потребно да у Makefile додамо правила за превођење класа за функције као и за табелу симбола.
Makefile
CC = g++
CFLAGS = -Wall -Wextra
parser: lex.yy.o parser.tab.o funkcija.o tabela_simbola.o
$(CC) $(CFLAGS) $^ -o $@
lex.yy.o: lex.yy.c funkcija.hpp
$(CC) $(CFLAGS) -c $< -o $@
lex.yy.c: lexer.l parser.tab.hpp
flex --nounput $<
parser.tab.o: parser.tab.cpp parser.tab.hpp funkcija.hpp tabela_simbola.hpp
$(CC) $(CFLAGS) -c $< -o $@
parser.tab.cpp parser.tab.hpp: parser.ypp
bison --header $<
funkcija.o: funkcija.cpp funkcija.hpp
$(CC) $(CFLAGS) -c $< -o $@
tabela_simbola.o: tabela_simbola.cpp tabela_simbola.hpp
$(CC) $(CFLAGS) -c $< -o $@
.PHONY: clean
clean:
rm -f *.o parser lex.yy.c parser.tab.*Након превођења и покретања над примером:
f = sin(x)
f'
f[1]
g = 1 + f(x*x)
g
g[0.5]
g'
g'[0.5]Добијамо наредни излаз:
(cos(x)) * (1)
0.841471
(1) + (sin((x) * (x)))
1.2474
(0) + ((cos((x) * (x))) * (((1) * (x)) + ((x) * (1))))
0.968912
prihvacenoШто је очекивани излаз—интерпретер ради!
Можемо још да га тестирамо за цурење меморије помоћу Valgrind-а. Ако се позиционирамо у одговарајући директоријум као на GitHub репозиторијуму, то можемо да урадимо командом:
valgrind ./parser < ../testСинтаксно стабло
У другом делу задатка од нас се захтева да формирамо синтаксно стабло које може да се исписује и интерпретира. Ово радимо тако што:
- задржавамо идентичну граматику и лексер који смо до сада записали (практично крећемо од стања
parser.yppфајла као после писања чистог парсера, а пре писања интерпретера) - зато што је потребно да интерпретирамо стабло, користићемо све класе које смо писали за интерпретер, дакле, задржавамо све до сада написане класе
- додајемо нове класе које представљају чворове синтаксног стабла тј. правимо фајлове
sintaksno_stablo.hppиsintaksno_stablo.cpp - додајемо акције у правила граматике која формирају стабло
Укратко, задржавамо већину ствари које смо већ написали, а остаје да направимо класе које представљају чворове синтаксног стабла и да додамо одговарјуће акције у већ написаним правилима граматике.
Крећемо са писањем класа чворова синтаксног стабла.
Правимо сличну хијерархију као раније, на чијем се врху налази класа ASTCvor.
Биће нам потребна по класа за сваки тип чвора, што ће практично бити по класа за свако правило у граматици.
Поред тога, направићемо и апстрактне класе посреднике за чворове са тачно једним, односно тачно два детета (класе UnarniCvor и BinarniCvor).
Класе са тачно једним дететом ће бити следеће:
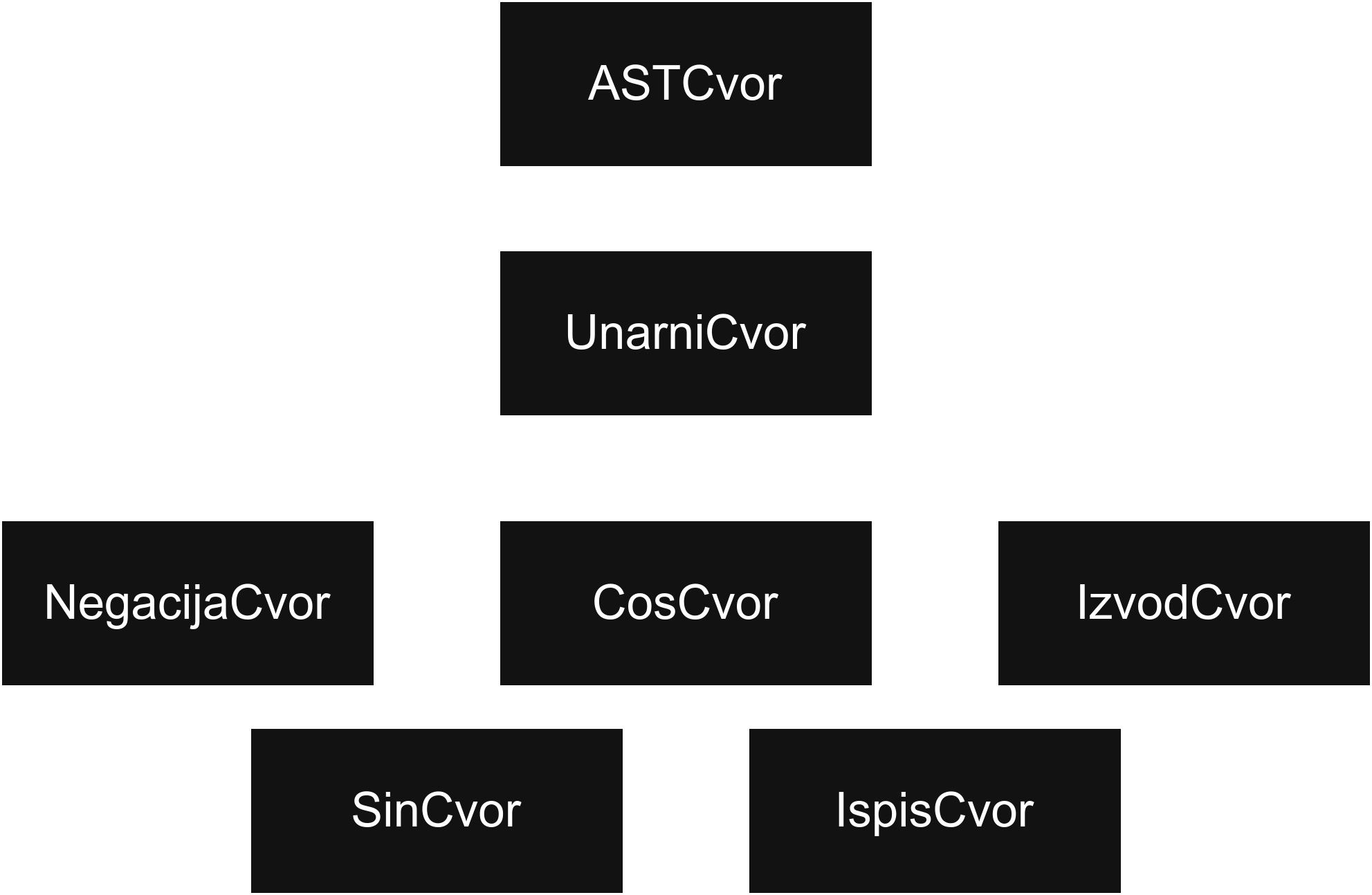
Са тачно два детета:
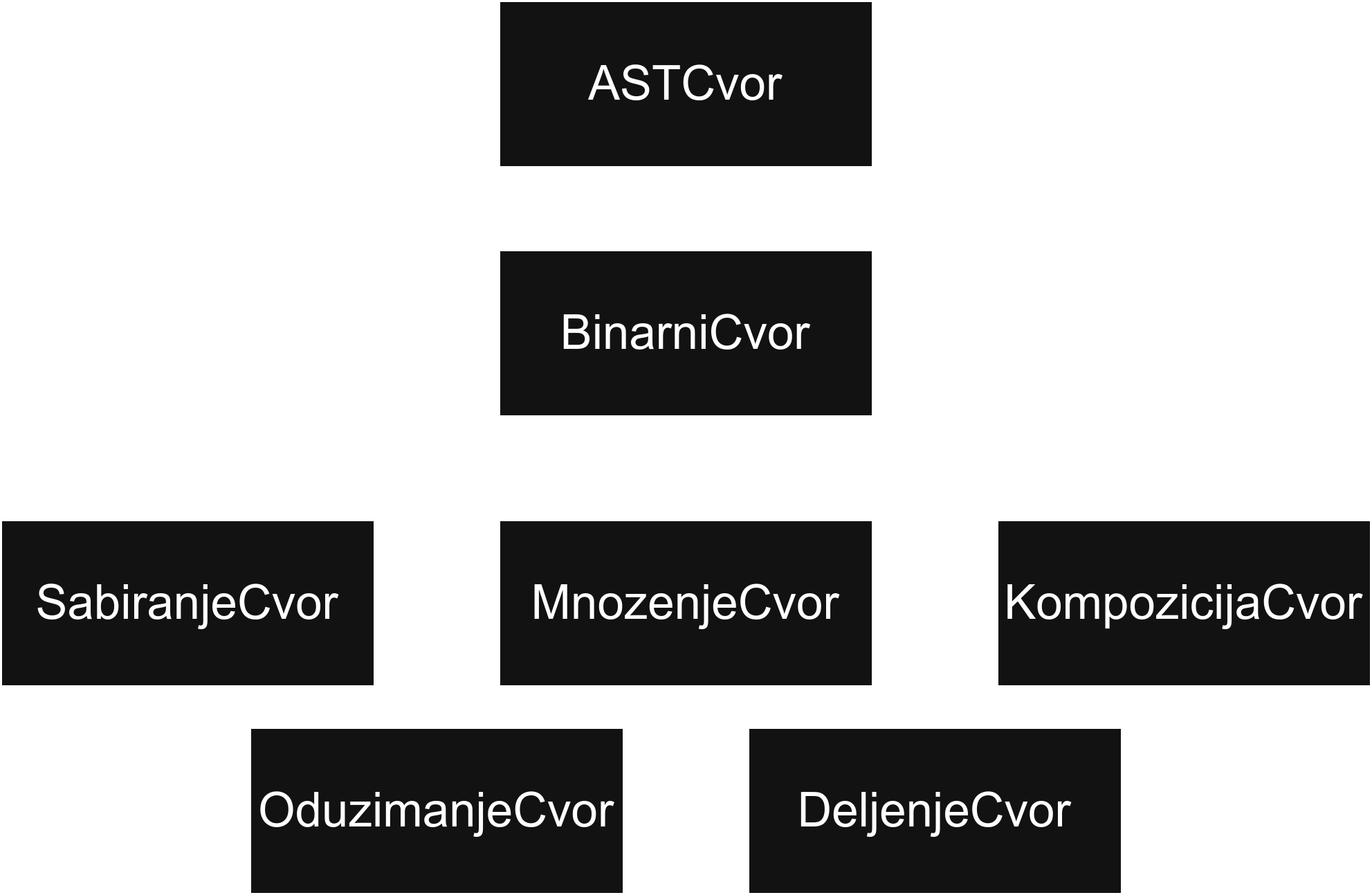
И преостале:
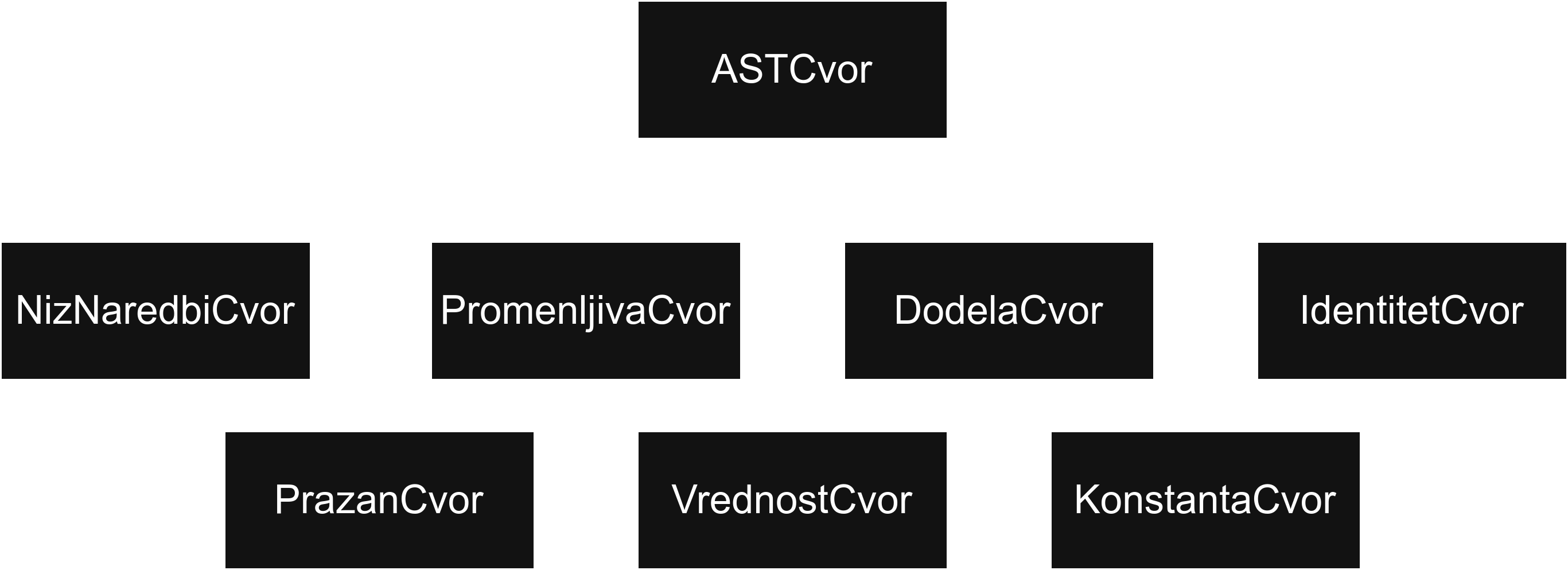
Напомена: Приметимо да овде правимо нове класе за све типове функција. То може да изгледа непотребно с обзиром да смо правили по класу са сваки тип функције код интерпретације. Међутим, ово је заправо врло важан моменат и једна од главних порука коју треба извући из овог задатка—а то је разумети шта то синтаксно стабло треба да представља.
Синтаксно стабло је стурктура података која представља изворни код програма и приликом његове конструкције треба се фокусирати само на то. Дакле, правимо по чвор за сваки синтакснички конструкт програма и не посвећујемо посебно пажњу самом извршавању програма. Ипак, ако желимо да интерпретирамо синтаксно стабло, биће потребно да обрадимо и семантику (што ћемо радити кроз методу
interpretiraj) и тада (и само ту) ћемо користити већ написане класе за функције.
У наставку ће бити приказане имплементације свих поменутих класа. Како је већина њих практично идентична класама из одељка о синтаксним стаблима то ће бити прокоментарисане само разлике у односу на њих. Та сличност потврђује претходну напомену, односно, да сама конструкција синтаксних стабала не зависи превише од семантике програма.
Класа ASTCvor и њене поткласe
Класа ASTCvor је стандардна.
Потребно је да имамо испис и интерпретацију синтаксног стабла, и то ће бити најважније функције које ће сваки чвор морати да имплементира.
Повратна вредност методе interpretiraj ће (по договору) бити тип израза са којима радимо у програму (подсетник).
Укратко, то радимо зато што желимо да неке методе (попут SabiranjeCvor и SinCvor) враћају функције, док неке друге (попут IpsisCvor) не треба да враћају ништа.
Решење које бирамо је да у самој декларацији методе поставимо повратну вредност на тип израза са којима радимо, и враћамо објекте тог типа у методама где то има смисла, док у осталима враћамо неку насумичну вредност.
Поред тога, овде радимо са сложеним типом података, па користимо показивач на функције тј. повратна вредност је Funkcija *.
Обратите пажњу да ћемо у чворовима синтаксног стабла који одговарају функцијама приликом интерпретације користити одговарајуће класе функције.
На пример, приликом интерпретирања класе SinCvor ће се враћати објекат типа SinFunkcija.
Слично и за остале.
sintaksno_stablo.hpp
class ASTCvor {
public:
virtual ~ASTCvor();
virtual void ispisi(std::ostream &os) const = 0;
virtual Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const = 0;
virtual ASTCvor *kloniraj() const = 0;
};
std::ostream &operator<<(std::ostream &os, const ASTCvor &ast_cvor);sintaksno_stablo.cpp
ASTCvor::~ASTCvor() {}
std::ostream &operator<<(std::ostream &os, const ASTCvor &ast_cvor) {
ast_cvor.ispisi(os);
return os;
}
Класа
NizNaredbiCvor
Ова класа је стандардна.
sintaksno_stablo.cpp
class NizNaredbiCvor : public ASTCvor {
public:
NizNaredbiCvor();
NizNaredbiCvor(const NizNaredbiCvor &drugi);
~NizNaredbiCvor();
void dodaj_cvor(ASTCvor *cvor);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
private:
std::vector<ASTCvor *> m_naredbe;
};sintaksno_stablo.cpp
NizNaredbiCvor::NizNaredbiCvor() {}
NizNaredbiCvor::NizNaredbiCvor(const NizNaredbiCvor &drugi) {
m_naredbe.resize(drugi.m_naredbe.size());
for (size_t i = 0; i < drugi.m_naredbe.size(); i++) {
m_naredbe[i] = drugi.m_naredbe[i]->kloniraj();
}
}
NizNaredbiCvor::~NizNaredbiCvor() {
for (ASTCvor *cvor : m_naredbe) {
delete cvor;
}
}
void NizNaredbiCvor::dodaj_cvor(ASTCvor *cvor) {
m_naredbe.push_back(cvor);
}
void NizNaredbiCvor::ispisi(std::ostream &os) const {
for (ASTCvor *cvor : m_naredbe) {
os << *cvor << "\n";
}
}
Funkcija *NizNaredbiCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
for (ASTCvor *cvor : m_naredbe) {
cvor->interpretiraj(tabela_simbola);
}
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return nullptr;
}
ASTCvor *NizNaredbiCvor::kloniraj() const {
return new NizNaredbiCvor(*this);
}
Класа
DodelaCvor
Такође стандардна класа иако радимо са сложеним типом података.
Сва позадинска логика за рад са сложеним типом који овде користимо је сакривена у класи TabelaSimbola.
sintaksno_stablo.hpp
class DodelaCvor : public ASTCvor {
public:
DodelaCvor(const std::string &id, ASTCvor *izraz);
DodelaCvor(const DodelaCvor &drugi);
~DodelaCvor();
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
private:
std::string m_id;
ASTCvor *m_izraz;
};sintaksno_stablo.cpp
DodelaCvor::DodelaCvor(const std::string &id, ASTCvor *izraz)
: m_id(id), m_izraz(izraz) {}
DodelaCvor::DodelaCvor(const DodelaCvor &drugi) {
m_id = drugi.m_id;
m_izraz = drugi.m_izraz->kloniraj();
}
DodelaCvor::~DodelaCvor() {
delete m_izraz;
}
void DodelaCvor::ispisi(std::ostream &os) const {
os << m_id << " = " << *m_izraz;
}
Funkcija *DodelaCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
tabela_simbola.dodeli_vrednost(m_id, m_izraz->interpretiraj(tabela_simbola));
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return nullptr;
}
ASTCvor *DodelaCvor::kloniraj() const {
return new DodelaCvor(*this);
}
Класа
PrazanCvor
Класа која представља празну наредбу.
Потребна нам је јер желимо да омогућимо да имамо празне линије у нашем програму.
Како нови ред разваја наредбе, то ће празни редови заправо представљати празне наредбе које ћемо морати да обрадимо током парсирања и обилажења наредба (погледати како обрађујемо нетерминал niz_naredbi у делу о акцијама).
sintaksno_stablo.hpp
class PrazanCvor : public ASTCvor {
public:
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
void PrazanCvor::ispisi(std::ostream &os) const {}
Funkcija *PrazanCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return nullptr;
}
ASTCvor *PrazanCvor::kloniraj() const {
return new PrazanCvor(*this);
}
Класа
PromenljivaCvor
Стандардна класа уз разлику да радимо са сложеним типом података. Зато променљиве чувају показиваче на динамички алоцирану меморију, и током интерпретације треба да правимо копије објеката који враћа табела симбола.
sintaksno_stablo.hpp
class PromenljivaCvor : public ASTCvor {
public:
PromenljivaCvor(const std::string &id);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
private:
std::string m_id;
};sintaksno_stablo.cpp
PromenljivaCvor::PromenljivaCvor(const std::string &id)
: m_id(id) {}
void PromenljivaCvor::ispisi(std::ostream &os) const {
os << m_id;
}
Funkcija *PromenljivaCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return tabela_simbola.vrednost_promenljive(m_id)->kloniraj();
}
ASTCvor *PromenljivaCvor::kloniraj() const {
return new PromenljivaCvor(*this);
}
Класа
VrednostCvor
Класа која одговара рачунању вредности функцје у тачки (изрази попут f[1]).
Декларација је праволинијска.
sintaksno_stablo.hpp
class VrednostCvor : public ASTCvor {
public:
VrednostCvor(ASTCvor *izraz, double vrednost);
VrednostCvor(const VrednostCvor &drugi);
~VrednostCvor();
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
private:
ASTCvor *m_izraz;
double m_vrednost;
};Међутим, код имплементације се јавља једна финеса у методи interpretiraj.
Оно што желимо да овај чвор ради приликом интерпретације је да интерпретира своје дете (m_cvor) и позове методу izracunaj над тако добијеним објектом.
Односно, следеће:
sintaksno_stablo.cpp
Funkcija *VrednostCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new KonstantnaFunkcija(
m_izraz->interpretiraj(tabela_simbola)->izracunaj(m_vrednost)
);
}Ово је семантички потпуно исправно, али доводи до цурења меморије. Наиме, позив
m_izraz->interpretiraj(tabela_simbola)враћа показивач на новоалоцирани објекат типа Funkcija.
Затим се над тим објектом позива метода izracunaj који рачуна тражену вредност, и то се пакује у константу функцију.
Проблем овде је што нигде не ослобађамо меморију коју је поменути позив алоцирао.
То решавамо тако што чувамо тај привремени резултат у променљивој над којом ћемо да позовемо екслицитно деструктор касније. Једно исправно решење може да буде овако:
sintaksno_stablo.cpp
Funkcija *VrednostCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
Funkcija *funkcija = m_izraz->interpretiraj(tabela_simbola);
Funkcija *vrednost = new KonstantnaFunkcija(
funkcija->izracunaj(m_vrednost)
);
delete funkcija;
return vrednost;
}Имплементација осталих метода је стандардна.
sintaksno_stablo.cpp
VrednostCvor::VrednostCvor(ASTCvor *izraz, double vrednost)
: m_izraz(izraz), m_vrednost(vrednost) {}
VrednostCvor::VrednostCvor(const VrednostCvor &drugi) {
m_izraz = drugi.m_izraz->kloniraj();
m_vrednost = drugi.m_vrednost;
}
VrednostCvor::~VrednostCvor() {
delete m_izraz;
}
void VrednostCvor::ispisi(std::ostream &os) const {
os << *m_izraz << "[" << m_vrednost << "]";
}
ASTCvor *VrednostCvor::kloniraj() const {
return new VrednostCvor(*this);
}
Класа
KonstantaCvor
sintaksno_stablo.hpp
class KonstantaCvor : public ASTCvor {
public:
KonstantaCvor(double vrednost);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
private:
double m_vrednost;
};sintaksno_stablo.cpp
KonstantaCvor::KonstantaCvor(double vrednost) : m_vrednost(vrednost) {}
void KonstantaCvor::ispisi(std::ostream &os) const {
os << m_vrednost;
}
Funkcija *KonstantaCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new KonstantnaFunkcija(m_vrednost);
}
ASTCvor *KonstantaCvor::kloniraj() const {
return new KonstantaCvor(*this);
}
Класа
IdentitetCvor
sintaksno_stablo.hpp
class IdentitetCvor : public ASTCvor {
public:
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
void IdentitetCvor::ispisi(std::ostream &os) const {
os << "x";
}
Funkcija *IdentitetCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new IdentitetFunkcija();
}
ASTCvor *IdentitetCvor::kloniraj() const {
return new IdentitetCvor(*this);
}Класа UnarniCvor и њене поткласe
Помоћна апстрактна класа која представља чворове синтаксног стабла са тачно једним чвором-дететом. Имплементација је стандардна.
sintaksno_stablo.hpp
class UnarniCvor : public ASTCvor {
public:
UnarniCvor(ASTCvor *cvor);
UnarniCvor(const UnarniCvor &drugi);
~UnarniCvor();
// metode iz natklase
virtual void ispisi(std::ostream &os) const = 0;
virtual Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const = 0;
virtual ASTCvor *kloniraj() const = 0;
protected:
ASTCvor *m_cvor;
};sintaksno_stablo.cpp
UnarniCvor::UnarniCvor(ASTCvor *cvor) : m_cvor(cvor) {}
UnarniCvor::UnarniCvor(const UnarniCvor &drugi) {
m_cvor = drugi.m_cvor->kloniraj();
}
UnarniCvor::~UnarniCvor() {
delete m_cvor;
}Имплементације њених поткласа ће такође већином бити стандардне. Само треба обратити пажњу на цурење меморије јер програм ради са сложеним типом података због чега се на неким местима јављају показивачи на динамички алоцирану меморију.
Треба приметити да је имплементација методе interpretiraj чворова који представљају функције врло једноставна јер ту користимо претходно написане класе за функције.
На пример, у интерпретацији класе SinCvor враћамо функцију SinFunkcija.
Овде је битно видети разлику између њих и зашто је потребно имати обе групе класа—класе синтаксног стабла само представљају чворове синтаксног стабла, док функције које смо писали за интерпретацију користимо само приликом интерпретирања тј. давања семантике програму.
Класа
NegacijaCvor
sintaksno_stablo.hpp
class NegacijaCvor : public UnarniCvor {
public:
NegacijaCvor(ASTCvor *cvor);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
NegacijaCvor::NegacijaCvor(ASTCvor *cvor) : UnarniCvor(cvor) {}
void NegacijaCvor::ispisi(std::ostream &os) const {
os << "- (" << *m_cvor << ")";
}
Funkcija *NegacijaCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new NegacijaFunkcija(m_cvor->interpretiraj(tabela_simbola));
}
ASTCvor *NegacijaCvor::kloniraj() const {
return new NegacijaCvor(*this);
}
Класа
SinCvor
sintaksno_stablo.hpp
class SinCvor : public UnarniCvor {
public:
SinCvor(ASTCvor *cvor);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
SinCvor::SinCvor(ASTCvor *cvor) : UnarniCvor(cvor) {}
void SinCvor::ispisi(std::ostream &os) const {
os << "sin(" << *m_cvor << ")";
}
Funkcija *SinCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new SinFunkcija(m_cvor->interpretiraj(tabela_simbola));
}
ASTCvor *SinCvor::kloniraj() const {
return new SinCvor(*this);
}
Класа
CosCvor
sintaksno_stablo.hpp
class CosCvor : public UnarniCvor {
public:
CosCvor(ASTCvor *cvor);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
CosCvor::CosCvor(ASTCvor *cvor) : UnarniCvor(cvor) {}
void CosCvor::ispisi(std::ostream &os) const {
os << "cos(" << *m_cvor << ")";
}
Funkcija *CosCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new CosFunkcija(m_cvor->interpretiraj(tabela_simbola));
}
ASTCvor *CosCvor::kloniraj() const {
return new CosCvor(*this);
}
Класа
IspisCvor
Овде треба да ослободимо меморију приликом интерпретације слично као у класи VrednostCvor.
sintaksno_stablo.hpp
class IspisCvor : public UnarniCvor {
public:
IspisCvor(ASTCvor *cvor);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
IspisCvor::IspisCvor(ASTCvor *cvor) : UnarniCvor(cvor) {}
void IspisCvor::ispisi(std::ostream &os) const {
os << *m_cvor;
}
Funkcija *IspisCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
Funkcija *vrednost = m_cvor->interpretiraj(tabela_simbola);
std::cout << *vrednost << std::endl;
delete vrednost;
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return nullptr;
}
ASTCvor *IspisCvor::kloniraj() const {
return new IspisCvor(*this);
}
Класа
IzvodCvor
Овде такође треба ослободити меморију приликом интерпретација на већ приказани начин (као у класама VrednostCvor и IspisCvor).
sintaksno_stablo.hpp
class IzvodCvor : public UnarniCvor {
public:
IzvodCvor(ASTCvor *cvor);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
IzvodCvor::IzvodCvor(ASTCvor *cvor) : UnarniCvor(cvor) {}
void IzvodCvor::ispisi(std::ostream &os) const {
os << "(" << *m_cvor << ")'";
}
Funkcija *IzvodCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
Funkcija *vrednost = m_cvor->interpretiraj(tabela_simbola);
Funkcija *izvod = vrednost->izvod();
delete vrednost;
return izvod;
}
ASTCvor *IzvodCvor::kloniraj() const {
return new IzvodCvor(*this);
}Класа BinarniCvor и њене поткласe
Помоћна апстрактна класа која представља чворове синтаксног стабла са тачно два чвор-детета. Имплементација је стандардна.
sintaksno_stablo.hpp
class BinarniCvor : public ASTCvor {
public:
BinarniCvor(ASTCvor *levi, ASTCvor *desni);
BinarniCvor(const BinarniCvor &drugi);
~BinarniCvor();
// metode iz natklase
virtual void ispisi(std::ostream &os) const = 0;
virtual Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const = 0;
virtual ASTCvor *kloniraj() const = 0;
protected:
ASTCvor *m_levi, *m_desni;
};sintaksno_stablo.cpp
BinarniCvor::BinarniCvor(ASTCvor *levi, ASTCvor *desni)
: m_levi(levi), m_desni(desni) {}
BinarniCvor::BinarniCvor(const BinarniCvor &drugi) {
m_levi = drugi.m_levi->kloniraj();
m_desni = drugi.m_desni->kloniraj();
}
BinarniCvor::~BinarniCvor() {
delete m_levi;
delete m_desni;
}Наредне поткласе имају стандардну имплементацију уз изузетак KompozicijaCvor класе где треба експлицитно позвати деструктор приликом интерпретације да би се спречило цурење меморије (што је такође већ виђено у класама VrednostCvor, IspisCvor и IzvodCvor).
Класа
SabiranjeCvor
sintaksno_stablo.hpp
class SabiranjeCvor : public BinarniCvor {
public:
SabiranjeCvor(ASTCvor *levi, ASTCvor *desni);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
SabiranjeCvor::SabiranjeCvor(ASTCvor *levi, ASTCvor *desni)
: BinarniCvor(levi, desni) {}
void SabiranjeCvor::ispisi(std::ostream &os) const {
os << "(" << *m_levi << ") + (" << *m_desni << ")";
}
Funkcija *SabiranjeCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new SabiranjeFunkcija(
m_levi->interpretiraj(tabela_simbola),
m_desni->interpretiraj(tabela_simbola)
);
}
ASTCvor *SabiranjeCvor::kloniraj() const {
return new SabiranjeCvor(*this);
}
Класа
OduzimanjeCvor
sintaksno_stablo.hpp
class OduzimanjeCvor : public BinarniCvor {
public:
OduzimanjeCvor(ASTCvor *levi, ASTCvor *desni);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
OduzimanjeCvor::OduzimanjeCvor(ASTCvor *levi, ASTCvor *desni)
: BinarniCvor(levi, desni) {}
void OduzimanjeCvor::ispisi(std::ostream &os) const {
os << "(" << *m_levi << ") - (" << *m_desni << ")";
}
Funkcija *OduzimanjeCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new OduzimanjeFunkcija(
m_levi->interpretiraj(tabela_simbola),
m_desni->interpretiraj(tabela_simbola)
);
}
ASTCvor *OduzimanjeCvor::kloniraj() const {
return new OduzimanjeCvor(*this);
}
Класа
MnozenjeCvor
sintaksno_stablo.hpp
class MnozenjeCvor : public BinarniCvor {
public:
MnozenjeCvor(ASTCvor *levi, ASTCvor *desni);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
MnozenjeCvor::MnozenjeCvor(ASTCvor *levi, ASTCvor *desni)
: BinarniCvor(levi, desni) {}
void MnozenjeCvor::ispisi(std::ostream &os) const {
os << "(" << *m_levi << ") * (" << *m_desni << ")";
}
Funkcija *MnozenjeCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new MnozenjeFunkcija(
m_levi->interpretiraj(tabela_simbola),
m_desni->interpretiraj(tabela_simbola)
);
}
ASTCvor *MnozenjeCvor::kloniraj() const {
return new MnozenjeCvor(*this);
}
Класа
DeljenjeCvor
sintaksno_stablo.hpp
class DeljenjeCvor : public BinarniCvor {
public:
DeljenjeCvor(ASTCvor *levi, ASTCvor *desni);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
DeljenjeCvor::DeljenjeCvor(ASTCvor *levi, ASTCvor *desni)
: BinarniCvor(levi, desni) {}
void DeljenjeCvor::ispisi(std::ostream &os) const {
os << "(" << *m_levi << ") / (" << *m_desni << ")";
}
Funkcija *DeljenjeCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
return new DeljenjeFunkcija(
m_levi->interpretiraj(tabela_simbola),
m_desni->interpretiraj(tabela_simbola)
);
}
ASTCvor *DeljenjeCvor::kloniraj() const {
return new DeljenjeCvor(*this);
}
Класа
KompozicijaCvor
sintaksno_stablo.hpp
class KompozicijaCvor : public BinarniCvor {
public:
KompozicijaCvor(ASTCvor *levi, ASTCvor *desni);
// metode iz natklase
void ispisi(std::ostream &os) const override;
Funkcija *interpretiraj(TabelaSimbola &tabela_simbola) const override;
ASTCvor *kloniraj() const override;
};sintaksno_stablo.cpp
KompozicijaCvor::KompozicijaCvor(ASTCvor *levi, ASTCvor *desni)
: BinarniCvor(levi, desni) {}
void KompozicijaCvor::ispisi(std::ostream &os) const {
os << *m_levi << "(" << *m_desni << ")";
}
Funkcija *KompozicijaCvor::interpretiraj(TabelaSimbola &tabela_simbola) const {
Funkcija *leva = m_levi->interpretiraj(tabela_simbola);
Funkcija *desna = m_desni->interpretiraj(tabela_simbola);
Funkcija *kompozicija = leva->komponuj(desna);
delete leva;
delete desna;
return kompozicija;
}
ASTCvor *KompozicijaCvor::kloniraj() const {
return new KompozicijaCvor(*this);
}Акције у Bison-у
Остаје нам на крају да додамо акције парсеру за формирање синтаксног стабла приликом парсирања. Као што смо већ приметили, направили смо по класу за сваки синтаксички конструкт нашег језика, што практично значи да имамо по класу за свако правило граматике. Зато ће се попуњавање акције углавном сводити на креирање објеката-чворова одговарајућег типа.
Тако акције за правила нетерминала izraz могу да изгледају овако:
parser.ypp
izraz
: izraz '+' izraz {
$$ = new SabiranjeCvor($1, $3);
}
| izraz '-' izraz {
$$ = new OduzimanjeCvor($1, $3);
}
| izraz '*' izraz {
$$ = new MnozenjeCvor($1, $3);
}
| izraz '/' izraz {
$$ = new DeljenjeCvor($1, $3);
}
| '-' izraz %prec UMINUS {
$$ = new NegacijaCvor($2);
}
| '(' izraz ')' {
$$ = $2;
}
| izraz '\'' {
$$ = new IzvodCvor($1);
}
| izraz '[' BROJ ']' {
$$ = new VrednostCvor($1, $3);
}
| izraz '(' izraz ')' {
$$ = new KompozicijaCvor($1, $3);
}
| SIN '(' izraz ')' {
$$ = new SinCvor($3);
}
| COS '(' izraz ')' {
$$ = new CosCvor($3);
}
| BROJ {
$$ = new KonstantaCvor($1);
}
| ID {
$$ = new PromenljivaCvor(*$1);
delete $1;
}
| PROMENLJIVA {
$$ = new IdentitetCvor();
}
;Даље, правила за наредбе су следећа:
parser.ypp
naredba
: ID '=' izraz '\n' {
$$ = new DodelaCvor(*$1, $3);
delete $1;
}
| izraz '\n' {
$$ = new IspisCvor($1);
}
| '\n' {
$$ = new PrazanCvor();
}
;Остају правила за niz_naredbi која су стандардна, односно:
parser.ypp
niz_naredbi
: niz_naredbi naredba {
NizNaredbiCvor *niz_naredbi_cvor = dynamic_cast<NizNaredbiCvor *>($$);
niz_naredbi_cvor->dodaj_cvor($2);
$$ = niz_naredbi_cvor;
}
| naredba {
NizNaredbiCvor *niz_naredbi_cvor = new NizNaredbiCvor();
niz_naredbi_cvor->dodaj_cvor($1);
$$ = niz_naredbi_cvor;
}
;Сада можемо јасније да видимо зашто је било потребно да имамо класу за празну наредбу. Наиме, приликом парсирања правила за
niz_naredbiдодајемо сваку наредбу програма у вектор који представља низ наредби. Ако бисмо оставили само празну акцију у правилуnaredba -> '\n'додавали бисмо невалидне вредности у поменути вектор што би резултовало грешком приликом извршавања.
На самом крају треба сачувати тако формирано синтаксно стабло. То радимо тако што у сегменту дефиниција декларишемо глобалну променљиву која ће чувати корен синтаксног стабла.
parser.ypp
%{
ASTCvor *ast = nullptr;
%}И додајемо акцију за правило акциоме:
parser.ypp
program
: niz_naredbi {
ast = $1;
}
;Када се парсирање заврши, имаћемо синтаксно стабло на располагању у променљивој ast.
Сада у сегменту корисничког кода можемо да је користимо тако што над њом позивамо одговарајуће методе за испис или интерпретацију.
parser.ypp
int main() {
if (yyparse() == 0) {
std::cout << "prihvaceno" << std::endl;
}
std::cout << *ast << std::endl;
TabelaSimbola tabela_simbola;
ast->interpretiraj(tabela_simbola);
delete ast;
yylex_destroy();
return 0;
}Треба још дефинисати тип који ће нетерминали чувати, што ће овде бити ASTCvor *.
Зато у сегменту дефиниција додајемо још:
parser.ypp
%union {
double realan_broj;
std::string *niska;
ASTCvor *ast_cvor;
}
%token SIN COS PROMENLJIVA
%token<niska> ID
%token<realan_broj> BROJ
%type<ast_cvor> program niz_naredbi naredba izrazКоначно допуњавамо Makefile са одговарајућим акцијама за превођење фајлова за синтаксно стабло.
Makefile
CC = g++
CFLAGS = -Wall -Wextra
parser: lex.yy.o parser.tab.o tabela_simbola.o funkcija.o sintaksno_stablo.o
$(CC) $(CFLAGS) $^ -o $@
lex.yy.o: lex.yy.c
$(CC) $(CFLAGS) -c $< -o $@
lex.yy.c: lexer.l parser.tab.hpp
flex --nounput $<
parser.tab.o: parser.tab.cpp parser.tab.hpp tabela_simbola.hpp funkcija.hpp
$(CC) $(CFLAGS) -c $< -o $@
parser.tab.cpp parser.tab.hpp: parser.ypp
bison --header $<
tabela_simbola.o: tabela_simbola.cpp tabela_simbola.hpp funkcija.hpp
$(CC) $(CFLAGS) -c $< -o $@
funkcija.o: funkcija.cpp funkcija.hpp
$(CC) $(CFLAGS) -c $< -o $@
sintaksno_stablo.o: sintaksno_stablo.cpp sintaksno_stablo.hpp tabela_simbola.hpp funkcija.hpp
$(CC) $(CFLAGS) -c $< -o $@
.PHONY: clean
clean:
rm -f *.o parser lex.yy.c parser.tab.*Превођењем и покретањем…
$ make$ ./parser < ../test… добијамо следећи испис:
prihvaceno
f = sin(x)
(f)'
f[1]
g = (1) + (f((x) * (x)))
g
g[0.5]
(g)'
(g)'[0.5]
(cos(x)) * (1)
0.841471
(1) + (sin((x) * (x)))
1.2474
(0) + ((cos((x) * (x))) * (((1) * (x)) + ((x) * (1))))
0.968912што је управо оно што желимо—стабло је исписано, а затим интерпретирано.
Да бисмо проверили да ли у нашем програму долази до цурења меморије, можемо да користимо Valgrind, и покренемо га на следећи начин:
$ valgrind ./parser < ../testУколико је све у реду (нема цурења меморије), добићемо наредни излаз:
All heap blocks were freed -- no leaks are possible
Претходно: Формирање синтаксног стабла уз GNU Bison
Следеће: Пример језика сличног Pascal-у
Додатак (shift и reduce акције)
Циљ овог додатка је да се детаљније опише процес парсирања у Bison-у. То је већ започето у поглављу како Bison извршава акције и пожељно је подсетити се тога пре читања даљег текста. Желимо да опишемо прецизније шта су то shift и reduce, као и како настају конфликти у граматици на (опет) површном нивоу, без улажења у детаље изгенерисаног потисног аутомата у позадини.
Нека нам је граматика језика иста као у остатку ове лекције и нека је, за почетак, на улазу реч
'(' izraz ')' '+' izraz
Поменули смо да се парсирање у позадини одвија навише, односно да парсер креће од речи са улаза и покушава да мења десне стране правила граматике левим. На мало детаљнијем нивоу, то се одвија приближно на следећи начин.
Парсер креће од речи и у чита је слева надесно.
Из тог разлога, уведимо посебан симбол • (тачку) која ће означавати где је парсер стигао са читањем улаза (на пример, почетно стање би било представљено са • '(' izraz ')' '+' izraz).
Поред тога, постојаће и један стек који ће се користити у позадини.
Током извршавања, парсер може да ради једну од две акције:
- shift – чита наредни терминал/нетерминал са улаза (овим се помера тачка удесно, а прочитани симбол ставља на стек)
- reduce – мења симболе са врха стека који чине десну страну неког правила граматике левом
Објаснимо то на примеру, симулацијом једног извршавања, које можемо да опишемо на следећи начин:
| корак | стање | стек | акција |
|---|---|---|---|
| 1. | • '(' izraz ')' '+' izraz |
shift | |
| 2. | '(' • izraz ')' '+' izraz |
'(' |
shift |
| 3. | '(' izraz • ')' '+' izraz |
'(' izraz |
shift |
| 4. | '(' izraz ')' • '+' izraz |
'(' izraz ')' |
reduce |
| 5. | '(' izraz ')' • '+' izraz |
izraz |
shift |
| 6. | '(' izraz ')' '+' • izraz |
izraz '+' |
shift |
| 7. | '(' izraz ')' '+' izraz • |
izraz '+' izraz |
reduce |
| 8. | '(' izraz ')' '+' izraz • |
izraz |
крај |
На почетку, у првом кораку, нисмо још увек ништа прочитали, па је тачка скроз лево, а стек је празан. Једино што можемо да урадимо је да читамо даље, дакле, радимо shift.
У другом кораку, на стеку је '('.
Међутим, то није десна страна ниједног правила, па не можемо да радимо reduce.
Опет нам остаје само да читамо даље тј. да радимо shift.
У трећем кораку, на стеку имамо '(' izraz (на стек додајемо са десне стране тј. izraz је на врху стека), што опет не представља десну страну неког правила.
Можемо само да радимо shift.
Међутим, у 4. кораку на стеку се појављује '(' izraz ')' што јесте десна страна једног од правила.
Зато у овом кораку можемо да радимо reduce.
То значи да тачка остаје на истом месту, али се стек мења—сви симболи са врха који су чинили десну страну правила се склањају, а уместо њих, на врх стека, долази лева страна правила тј. на стеку ће се налазити izraz.
У 5. кораку на стеку немамо десну страну правила па радимо shift тј. додајемо на стек симбол '+'.
У 6. кораку на стеку имамо izraz '+', па само можемо да радимо shift чиме долазимо до краја улаза.
У 7. кораку нам се на стеку појавио izraz '+' izraz што можемо да мењамо, те радимо reduce.
Тиме добијамо на стеку аксиому, при чему је улаз прочитан до краја што је знак да смо завршили и да је реч прихваћена.
Приметимо да је ово само детаљнији опис који је већ виђен у делу са акцијама. Тамо смо рекли да се акције придружене правилима граматике у Bison-у извршавају када заменимо десне стране правила левим. Сада видимо да се оне заправо извршавају када парсер уради reduce. Заиста, читањем претходнох извођења уназад, и посматрањем само корака са reduce акцијама, можемо да формирамо стабло извођења које смо помињали раније.
Хајде да сада анализирамо пример који нам генерише Bison за конфликте у граматици (са опцијом -Wcounterexamples).
Један од њих је:
parser.ypp: warning: shift/reduce conflict on token '\'' [-Wcounterexamples]
Example: izraz '+' izraz • '\''
Shift derivation
izraz
↳ 7: izraz '+' izraz
↳ 13: izraz • '\''
Reduce derivation
izraz
↳ 13: izraz '\''
↳ 7: izraz '+' izraz •Већ смо поменули да су нам прве две линије најзначајније, јер нам говоре ком токену треба да доделимо приоритет и дају нам пример где конфликт настаје.
Међутим, сада видимо и мало више.
Bison при исписивању примера користи симбол • који има исто значење које смо и ми користили изнад—представља место до ког је парсер стигао са читањем улаза.
Анализирајмо ово извођење у претходном стилу.
| корак | стање | стек | акција |
|---|---|---|---|
| 1. | • izraz '+' izraz '\'' |
shift | |
| 2. | izraz • '+' izraz '\'' |
izraz |
shift |
| 3. | izraz '+' • izraz '\'' |
izraz '+' |
shift |
| 4. | izraz '+' izraz • '\'' |
izraz '+' izraz |
? |
Извршавање се одвија слично као и у претходном примеру, али овог пута када дођемо до 4. корака не знамо шта да радимо. Наиме, на врху стека се налази десна страна једног правила, али можемо и да читамо даље (тачка није дошла до краја улаза). Дакле, можемо да урадимо shift, али и reduce—имамо shift/reduce конфликт.
Ако се одлучимо за shift, извршавање се одвија овако:
| 4. | izraz '+' izraz • '\'' |
izraz '+' izraz |
shift |
| 5. | izraz '+' izraz '\'' • |
izraz '+' izraz '\'' |
reduce |
| 6. | izraz '+' izraz '\'' • |
izraz '+' izraz |
reduce |
| 7. | izraz '+' izraz '\'' • |
izraz |
крај |
У овом случају, настављамо даље читање и додајемо '\'' на стек.
Када га додамо, онда на врху стека имамо izraz '\'' (приметимо да нам у овом тренутку није важан остатак стека), што је десна страна правила и радимо reduce.
Тиме на стеку добијамо izraz '+' izraz и још једним reduce завршавамо парсирање.
Са друге стране, ако се у 4. кораку одлучимо за reduce, извођење изгледа овако:
| 4. | izraz '+' izraz • '\'' |
izraz '+' izraz |
reduce |
| 5. | izraz '+' izraz • '\'' |
izraz |
shift |
| 6. | izraz '+' izraz '\'' • |
izraz '\'' |
reduce |
| 7. | izraz '+' izraz '\'' • |
izraz |
крај |
Зашто нисмо имали shift/reduce конфликт 4. кораку извођења у првом примеру? Шта би се догодило да је тада урађен shift? 1
Дакле, парсирање може да се изврши на два различита начина, а тиме имамо и другачија стабла извођења. Ако бисмо пратили reduce кораке, првом (shift) извођењу одговара наредно стабло извођења:
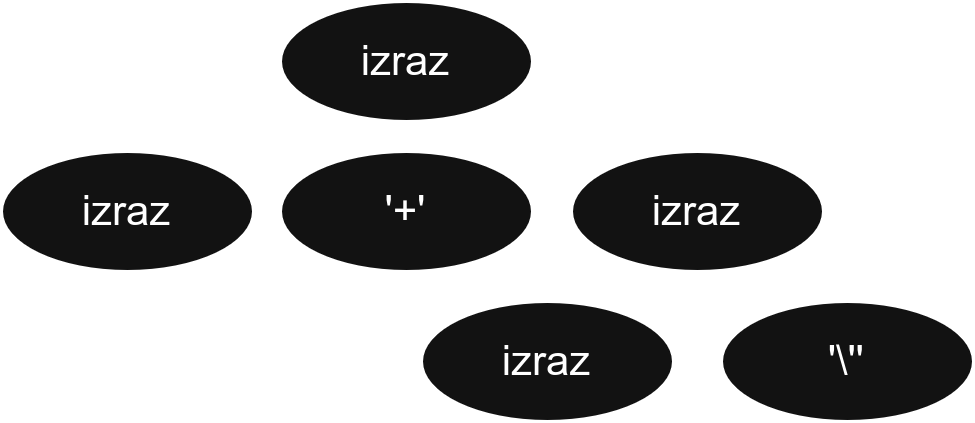
Док другом (reduce) извођењу одговара:
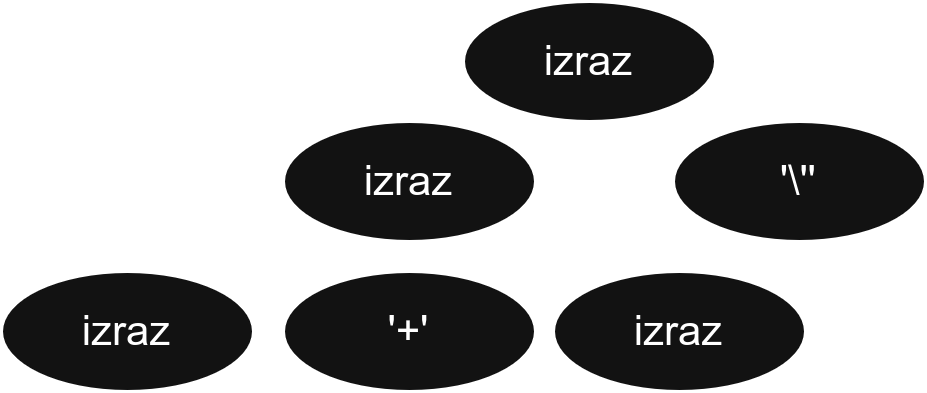
Јасно видимо да ће од акције у 4. кораку извођења зависити приоритет оператора сабирања и извода.
Сада можемо и да протумачимо цео испис генератора контрапримера.
parser.ypp: warning: shift/reduce conflict on token '\'' [-Wcounterexamples]
Example: izraz '+' izraz • '\''
Shift derivation
izraz
↳ 7: izraz '+' izraz
↳ 13: izraz • '\''
Reduce derivation
izraz
↳ 13: izraz '\''
↳ 7: izraz '+' izraz •Наиме, видимо за почетак да конфликт настаје када је тачка испред токена '\'', што смо и ми добили нашом анализом (у претходној терминологији, парсер је стигао до 4. корака).
Поред тога исписана су нам и два могућа извођења: shift и reduce извођење и приказана стабла тих извођења.
Разрешавање конфликата
Да бисмо решили овај конфликт неопходно је да кажемо парсеру која акција има приоритет у случају конфликта. У овом случају желимо прво извођење, односно треба да означимо да shift има предност у односу на reduce.
Приоритет акција можемо да посматрамо на следећи начин2:
-
приоритет shift акције одређује приоритет токена који ће бити прочитан
(у овом случају, када се одради shift у 4. кораку, чита се токен
'\''тј. shift акција ће имати приоритет токена'\'') -
приоритет reduce акције одређује приоритет правила које се користи приликом редуковања тј. правила чија се десна страна поклапа са врхом стека
(у овом случају, reduce у 4. кораку означава замену
izraz '+' izrazсаizrazтј. reduce акција ће имати приоритет правилаizraz -> izraz '+' izraz)
При чему је приоритет правила једнак приоритету последњег токена који се у њему појављује (нпр. приоритет правила izraz -> izraz '+' izraz је једнак приоритету токена '+').
Приоритет правила се може задати и директивом %prec TOKEN након правила.
Тиме се правилу додаје приоритет токена TOKEN.
Приметимо да смо то користили раније када смо решавали конфликт приоритета унарног минуса и писали смо
izraz: '-' izraz %prec UMINUS {...}
У овом конкретном примеру, желимо да се деси shift акција, чији је приоритет једнак приоритету одговарајућег токена који ће бити прочитан тј. токена '\'', у односу на reduce акцију чији је приоритет једнак приоритету правила izraz -> izraz '+' izraz тј. токена '+'.
Односно, потребно је да наведемо да токен '\'' има већи приоритет од токена '+', па у сегмент дефиниција додајемо:
parser.ypp
%left '+'
%right '\''Што је управо што смо и радили у нашој граматици да разрешимо конфликте.
Приметимо да се то поклапа са интуитивним схватањем да за разрешење приоритета између сабирања и извода, треба да дефинишемо приоритет токена '+' и '\''.
Међутим, интуиција није довољна у разешавању приоритета оператора [] и (), али претхода анализа једноставно објашњава како се тај проблем решава.
Видели смо да Bison генерише следеће контрапримере.
parser.ypp: warning: shift/reduce conflict on token '[' [-Wcounterexamples]
Example: izraz '+' izraz • '[' BROJ ']'parser.ypp: warning: shift/reduce conflict on token '(' [-Wcounterexamples]
Example: izraz '+' izraz • '(' izraz ')'Дакле, парсер креће од • izraz '+' izraz '[' BROJ ']' и након три shift акције се налази у стању izraz '+' izraz • '[' BROJ ']' где на располагању има две могућности: да ради shift (чита токен '[') или да ради reduce (по правилу izraz -> izraz '+' izraz).
Сада знамо да бисмо разрешили конфликт тј. да бисмо дали предност оператору [], треба да дамо предност shift акцији у односу на reduce.
Shift има приоритет који је једнак приоритету токена '[', док reduce има приоритет одговарајућег правила, дакле, последњег токена у том правилу, што је токен '+'.
Зато је за разрешавање довољно додати у сегменту дефиниција:
parser.ypp
%left '+'
%precedence '['Што се поклапа са оним што смо урадили иницијално у парсер фајлу.
Слично ситуација је код оператора ().
Попут shift/reduce конфликата, могу се јавити и reduce/reduce конфликти. Тада парсер може да ради reduce акцију по два различита правила и то је најчешће знак да нам граматика није добро написана и да је потребно преправити постојећа правила.
-
Да смо се одлучили за shift у 4. кораку извођења, на стек бисмо додали
'+', а потомizrazи добили на крају'(' izraz ')' '+' izraz. Међутим, ни у једном тренутку се на врху стека не би нашла десна страна неког правила и дошли бисмо до краја улаза, али на стеку не би остала аксиома. Дакле, не бисмо могли да завршимо извођење. Овде се поставља још једно питање: како парсер зна да не може да уради на том месту shift, док у другом примеру види да може и shift и reduce? Одговор лежи у оном делу који овде прећутно прелазимо, а то је рад LALR парсера. ↩ -
Детаљи се могу пронаћи у званичној документацији Bison-а. Поред поменутог, у документацији се могу пронаћи и повезани чланци који употпуњују ову причу. ↩