Формирање синтаксног стабла уз GNU Bison
Овде се подразумева познавање основа лексичке и синтаксичке анализе, као и алата за генерисање лексичких, односно синтаксичких, анализатора – Flex и Bison. Поред тога, потребно је и разумевање шта је апстрактно синтаксно стабло и како се оно може имплементирати у C++-у (то је покривено у лекцији о синтаксним стаблима).
Увод
Циљ овог дела је да комплетирамо претходно започету причу око синтаксних стабала. Већ смо направили структуру синтаксног стабла у C++-у и сада желимо да је искористимо у синтаксичкој анализи. То ћемо радити помоћу алата GNU Bison који смо већ користили за синтаксичку анализу. Уз њега, биће нам потребан и Flex за лексичку анализу.
Обично ће испитни задаци захтевати да се:
- направи интерпретер за дати програмски језик (што је онај део градива који је рађен до сада)
- измени интерпретер тако да као резултат буде синтаксно стабло (што је оно што сада желимо)
Друга ставка подразумева, да се искористи већ постојећи Bison фајл са постојећом граматиком и у њему измене акције и одговарајући типови тако да он као резултат формира синтаксно стабло. То је оно што желимо да урадимо у наставку.
Пример језика
Ради лакшег праћења, све наредне кодове можете пронаћи на GitHub репозиторијуму.
Нека имамо програмски језик који:
- ради са реалним бројевима
- омогућава дефинисање променљивих са иницијализацијом (наредбе типа
def x = 2.3) - омогућава доделу вредности променљивих (наредбе типа
x = x * y + 2) - омогућава исписивање вредности израза (наредбе типа
print(4.3 * ( - y + 2))) - омогућава поређење реалних израза на једнакост (наредбе типа
x == 2 * y + 1.5које на стандарни излаз исписујуTrue, односноFalse)
Желимо да направимо синтаксно стабло за овај језик над којим ћемо моћи да извршимо две операције:
- исписивање стабла, односно, одговарајући испис сваког његовог чвора (нека врста враћања у изворни код)
- интерпретација стабла (односно, његово извршавање)
Пример програма:
def x = 2.5;
x = x * x + 2;
print(- x);
16.5 == 2 * x;Овај исти пример смо видели у одељку за синтаксна стабла где је описано како се може направити структура синтаксног стабла за овај језик у C++-у, што ћемо да користимо овде.
На крају те лекције је и ручно направљено синтаксно стабло за баш претходни пример програма. Међутим, то није нешто што желимо да радимо, те зато овде желимо да тај процес аутоматизујемо, односно, да направимо програм који за произвољан изворни код на овом замишљеном језику формира синтаксно стабло.
То ћемо да урадимо коришћењем већ виђених техника помоћу Flex-а и Bison-а. Наиме, они за нас могу да одраде лексичку и синтаксичку анализу, а нама са друге стране треба да формирамо синтаксно стабло. Међутим, ако се сетимо начина на који Bison врши парсирање, а то је одоздо-навише, и да смо то парсирање тумачили као обилазак синтаксног стабла навише, видећемо да је то управо оно што нам и треба.
Bison ће за нас да „обилази“ улазни програм, док нама остаје да приликом поклапања граматичких правила, у акцијама креирамо одговарајуће чворове.
Дакле, вршићемо парсирање програма, односно, користићемо добро познату структуру пројекта која се састоји од:
lexer.lфајла на основу кога Flex формира лексички анализаторparser.yppфајла на основу кога Bison формира синтаксички анализаторMakefileкоји нам олакшава превођење читавог пројекта
Уз то, искористићемо и структуру синтаксног стабла коју смо претходно направили, па укључујемо још и:
sintaksno_stablo.hppsintaksno_stablo.cpptabela_simbola.hpptabela_simbola.cpp
фајлове, које ћемо да користимо у lexer.l и parser.ypp као готове структуре података (не заборавимо да укључимо табелу симбола која нам је потребна за интерпретацију синтаксног стабла).
Препорука: Ово је моменат где можете да покушате сами да урадите задатак. Дакле, треба направити програм који ће бити горенаведене структуре (исте као и у већ виђеним Bison задацима), а оно је што је ново (и главно) је попунити акције у
parser.yppфајлу тако да се током парсирања формира синтаксно стабло чије смо чворове већ имплементирали у C++-у раније.
Парсер за језик
Као што је већ поменуто, синтаксно стабло ћемо направити тако што ћемо само променити акције у Bison фајлу интерпретера. Дакле, биће нам потребно да направимо прво парсер за језик, па ћемо онда касније да попуњавамо одговарајуће акције.
Урадимо онда то.
Граматика језика
Као и у свим примерима до сада где смо правили интерпретер за неки језик, увек полазимо од граматике тог језика. Разлог за то је што ћемо на основу граматике да одређујемо који су нам токени потребни за лексер, а поред тога можемо добити и јаснију слику које су нам све класе потребне за синтаксно стабло.
Тако да попуњавамо сегмент акција у parser.ypp фајлу наредном контексно слободном граматиком.
Подсетник: Сваки Flex и Bison фајл се састоји из три дела
segment definicija %% segment akcija %% segment korisnickog koda
parser.ypp
program
: niz_naredbi {}
;
niz_naredbi
: niz_naredbi naredba {}
| naredba {}
;
naredba
: DEF ID '=' izraz ';' {}
| ID '=' izraz ';' {}
| PRINT '(' izraz ')' ';' {}
| izraz EQ izraz ';' {}
;
izraz
: izraz '+' izraz {}
| izraz '*' izraz {}
| '-' izraz {}
| '(' izraz ')' {}
| ID {}
| BROJ {}
;Као добру праксу, када пишемо граматику, одмах пишемо и празне акције (
{}). То је пожељно јер је подразумевана акција (уколико се ништа не напише)$$ = $1;. Зато, ако заборавимо да напишемо акцију касније, може доћи до неочекиваног понашања.
Ово је стандардна граматика коју смо имали прилике да видимо раније.
Програм доживљавамо као низ наредби, а низ наредби формирамо на стандардан начин (подсетимо се да је у правилу niz_naredbi: niz_naredbi naredba важан редослед нетерминала са десне стране, јер он одређује у ком ће се редоследу тумачити наредбе програма, нешто више о томе касније).
Затим, правила за нетерминал naredba треба да покрију све могуће типове наредби којих је овде четири, и све смо их навели.
Осим тога, ту имамо и правила за изразе који су такође стандардни.
Сада видимо који су токени потребни, па је неопходно и да их декларишемо у сегменту дефиниција.
parser.ypp
%token DEF PRINT EQ
%token BROJ
%token IDЈош једна ствар која се тиче граматике је да уклонимо вишезначност. Овде се она јавља јер нисмо нигде навели приоритет оператора у правилима за изразе. Зато треба додати у сегменту дефиниција још
parser.ypp
%left '+'
%left '*'
%right UMINUSДок у сегменту акција треба допунити правило за унарни минус
parser.ypp
izraz
...
| '-' izraz %prec UMINUS {}
...Приметимо да овде није било неопходно да се уведе нови терминал
UMINUSза разрешење вишезначности. Наиме, наш језик не подржава и одузимање и негацију (па да користи исти симбол за две различите операције). Зато је било довољно је само да напишемо%right '-'. Међутим, скоро увек ће бити неопходно да имамо и одузимање и негацију, и тада ће бити неопходно да разликујемо та два симбола, па је изабрано овакво решење.
Уколико смо заборавили да дефинишемо приоритете, приликом превођења ће нам Bison генерисати ипозорење о shift/reduce конфликтима. Ако нисмо сигурни на шта се они односе можемо да преведемо парсер фајл уз додатну опцију
-Wcounterexamplesкоја ће исписати примере конфликата.
Лексер
Већ смо одлучили који су нам токени потребни тако да можемо да направимо lexer.l фајл.
Његов садржај може бити следећи.
lexer.l
%option noyywrap
%{
#include <iostream>
#include <cstdlib>
#include "parser.tab.hpp"
%}
PRIR_BROJ 0|[1-9][0-9]*
REAL_BROJ [+-]?{PRIR_BROJ}(\.{PRIR_BROJ}([eE][+-]{PRIR_BROJ})?)?
IDENTIFIKATOR [_a-zA-Z][_a-zA-Z0-9]*
%%
def {
return DEF;
}
print {
return PRINT;
}
== {
return EQ;
}
{IDENTIFIKATOR} {
return ID;
}
{REAL_BROJ} {
return BROJ;
}
[+\-*()=;] {
return *yytext;
}
[ \t\n] {
}
. {
std::cerr << "leksicka greska: " << yytext << std::endl;
exit(EXIT_FAILURE);
}
%%Ово је стандардан Flex фајл који је већ виђен до сада.
Подсетимо се да је важно навести прво све кључне речи, па тек онда регуларни израз за идентификаторе.
У супротном би неке кључне речи (попут def) биле протумачене као идентификатори.
Повезивање
Сада желимо да спојимо све до сада, односно, да преведемо на одговарајући начин написане фајлове. Подсетник, то радимо тако што:
-
преведемо фајл за парсер
bison --header parser.ypp(опција
headerгенерише пропратниparser.tab.hppфајл који укључујемо у лексеру1). -
преведемо фајл за лексер
flex lexer.l(овде се може додати и опција
nounputкоја није неопходна, али служи да угуши каснија упозорења при превеђењу генерисаних C++ фајлова). -
преведемо све генерисане C++ фајлове
g++ -Wall -Wextra lex.yy.c parser.tab.cpp -o parser
Да бисмо олакшали процес превођења, као и до сада, користићемо Make, тако да ћемо направити Makefile са наредним садржајем.
Makefile
CC = g++
CFLAGS = -Wall -Wextra
parser: lex.yy.o parser.tab.o
$(CC) $(CFLAGS) $^ -o $@
lex.yy.o: lex.yy.c parser.tab.hpp
$(CC) $(CFLAGS) -c $< -o $@
lex.yy.c: lexer.l parser.tab.hpp
flex --nounput $<
parser.tab.o: parser.tab.cpp parser.tab.hpp
$(CC) $(CFLAGS) -c $< -o $@
parser.tab.cpp parser.tab.hpp: parser.ypp
bison --header $<
.PHONY: clean
clean:
rm -f *.o parser.tab.* lex.yy.c parser
$^,$<и$@су аутоматске променљиве и означавају:
$^- сви предуслови (све наведено после:)$<- први предуслов$@- име циља (правила)
Овде не наводимо потпуно исте команде као и ручно, већ при компилацији прво преводимо до објектних фајлова, а затим све објектне заједно преводимо до извршног. Разлог за то је да, ако променимо само један фајл, нема потребе да поново преводимо све остале, већ можемо да искористимо њихове постојеће објектне фајлове. Make препознаје у којим фајловима је дошло до измене и покреће само неопходне команде.
Остаје да напишемо сегмент корисничког кода у parser.ypp фајлу.
Ту је главно да позовемо функцију yyparse.
parser.ypp
int main() {
if (yyparse() == 0) {
std::cout << "prihvaceno" << std::endl;
}
// pozivamo desktuktor za lekser
yylex_destroy();
return 0;
}Дакле, ако се парсирање заврши без синтаксичких грешака (yyparse врати 0), онда ће наш парсер да испише prihvaceno.
У супротном биће исписана синтаксичка грешка помоћу функције yyerror (коју је неопходно да дефинишемо у сегменту дефиниција).
Коначно, покретањем
$ make
bison --header parser.ypp
flex --nounput lexer.l
g++ -Wall -Wextra -c lex.yy.c -o lex.yy.o
g++ -Wall -Wextra -c parser.tab.cpp -o parser.tab.o
g++ -Wall -Wextra lex.yy.o parser.tab.o -o parserпреводимо програм.
Ако сачувамо пример програма са почетка у текстуални фајл test, онда можемо да тестирамо парсер на следећи начин.
$ ./parser < test
prihvacenoОвим смо направили програм који испитује да ли улазни фајл припада контексно слободном језику нашег програма. Сада можемо коначно да се посветимо главном делу – писању одговарајућих акција.
Додавање акција
О акцијама у Bison-у
Подсетимо се како смо тумачили редослед примене правила у Bison-у. Нека имамо једноставну контексно слободну граматику, попут наредне.
izraz
: izraz '+' izraz
| izraz '*' izraz
| BROJ
;За улазну реч парсеру генерисаном Bison-ом, њена припадност граматици се проверава тако што се крене од саме те речи, и низом одговарајућих корака покушава да се добије аксиома граматике (почетни нетерминал).
Приметимо да је ово у супротности са самом дефиницијом припадности речи контексно слободној граматици и оним како смо ручно испитивали припадност.
Наиме, по дефиницији, реч припада граматици ако постоји извођење којим се од аксиоме добија та реч.
На пример, реч BROJ '+' BROJ '*' BROJ припадa полазној граматици јер постоји наредно извођење.
izraz
=> izraz '+' izraz (izraz => izraz '+' izraz)
=> izraz '+' izraz '*' izraz (izraz => izraz '*' izraz)
=> BROJ '+' izraz '*' izraz (izraz => BROJ)
=> BROJ '+' BROJ '*' izraz (izraz => BROJ)
=> BROJ '+' BROJ '*' BROJ (izraz => BROJ)Где под извођењем подразумевамо низ корака у коме се у сваком кораку један нетерминал са леве стране мења десном страном неког правила граматике.
Овакав приступ можемо и да опишемо стаблом извођења, које изгледа овако.
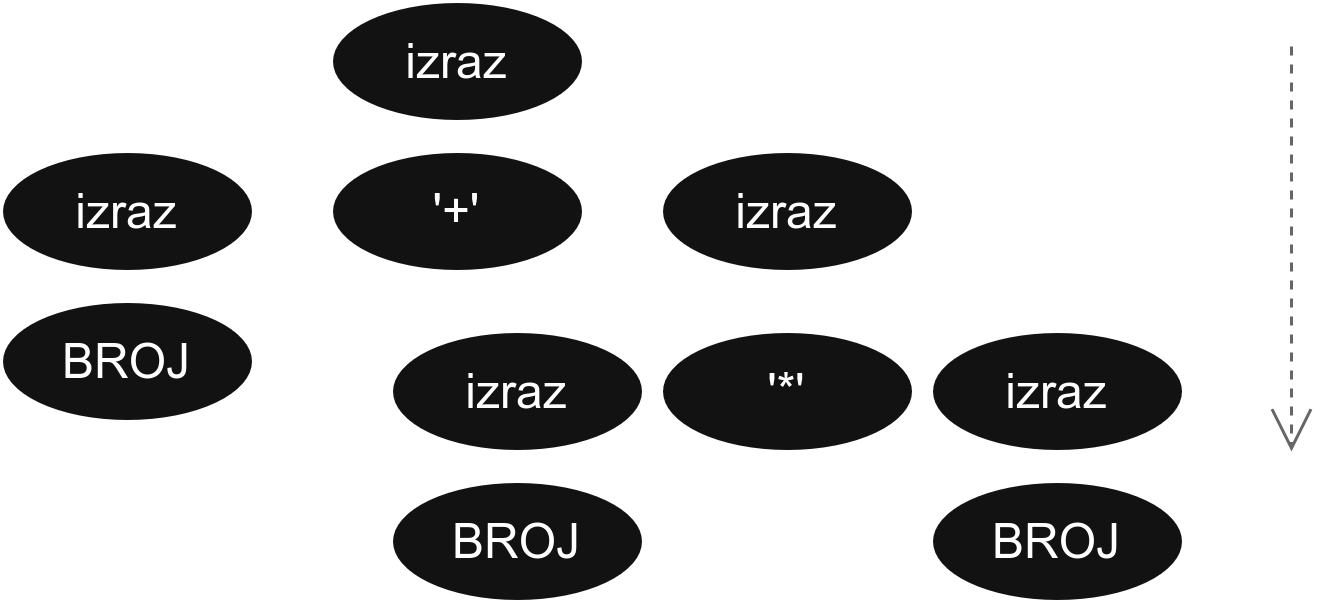
При чему овде стабло градимо од корена ка листовима тј. кренемо од аксиоме која је у корену стабла и када применимо правило додајемо одговарајуће чворове децу.
Међутим, можемо да испитамо припадност и на други начин. Тако што кренемо од саме речи, и покушамо да добијемо аксиому, при чему у сваком кораку мењамо десне стране правила граматике левим. На пример, на следећи начин.
BROJ '+' BROJ '*' BROJ
=> BROJ '+' BROJ '*' izraz (BROJ => izraz)
=> BROJ '+' izraz '*' izraz (BROJ => izraz)
=> izraz '+' izraz '*' izraz (BROJ => izraz)
=> izraz '+' izraz (izraz '*' izraz => izraz)
=> izraz (izraz '+' izraz => izraz)Дакле, кренули смо од речи чија нас припадност занима и дошли до аксиоме заменом десних страна правила левим (нпр. имали смо правило izraz -> izraz '+' izraz, и у неком од корака само заменили izraz '+' izraz са izraz).
Овде такође можемо да нацртамо стабло извођења које ће бити идентично претходном, само ће се начин на које се оно формира бити другачији. Биће креирано од листова ка корену, односно, навише.
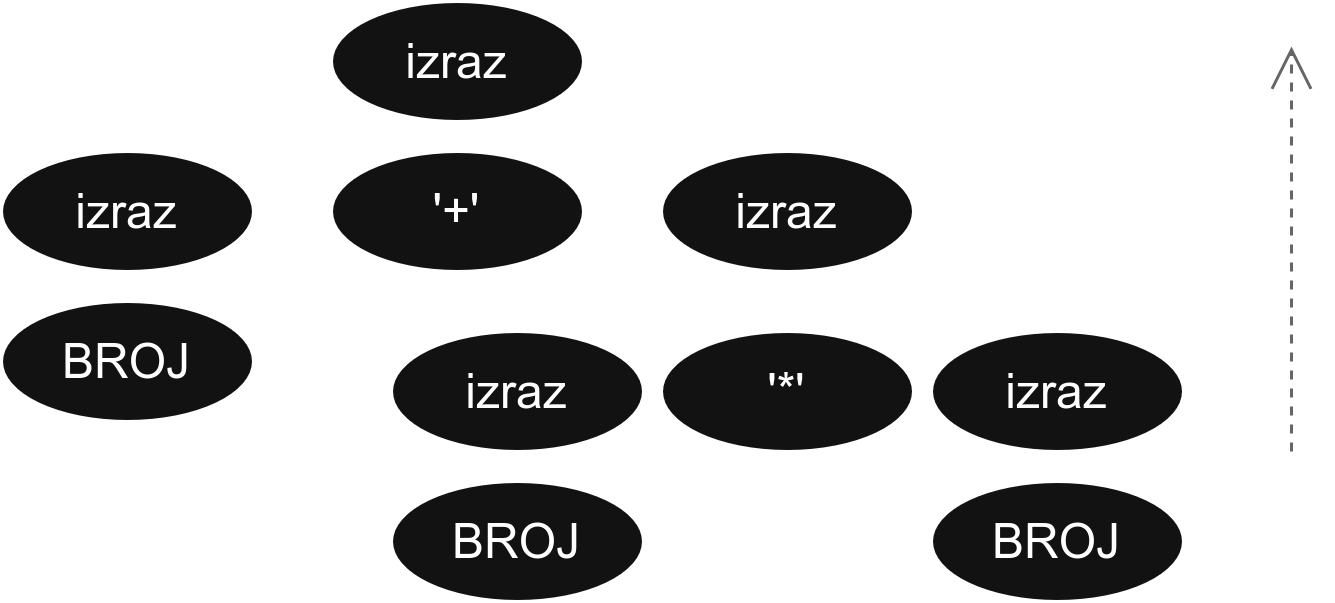
Можемо да тумачимо да Bison ради на тај начин у позадини. Да крене од целокупног улаза (који је токенизован, јер је прошао лексичку анализу) и да покушава да дође до аксиоме тако што у сваком кораку мења десну страну неког правила левом, а да сваки пут када уради ту замену изврши одговарајућу акцију.
На пример, ако додамо акције у полазној граматици.
izraz
: izraz '+' izraz {
std::cout << 1 << std::endl;
}
| izraz '*' izraz {
std::cout << 2 << std::endl;
}
| BROJ {
std::cout << 3 << std::endl;
}
;И, ако парсеру генерисаном Bison-ом, као улаз дамо реч BROJ '+' BROJ '*' BROJ, излаз ће бити:
3
3
3
2
1То можемо видети ако опет кренемо од полазне речи и исписујемо кораке редом.
BROJ '+' BROJ '*' BROJ
=> BROJ '+' BROJ '*' izraz (BROJ => izraz: pravilo 3)
=> BROJ '+' izraz '*' izraz (BROJ => izraz: pravilo 3)
=> izraz '+' izraz '*' izraz (BROJ => izraz: pravilo 3)
=> izraz '+' izraz (izraz '*' izraz => izraz: pravilo 2)
=> izraz (izraz '+' izraz => izraz: pravilo 1)Или можемо видети из стабла извођења.
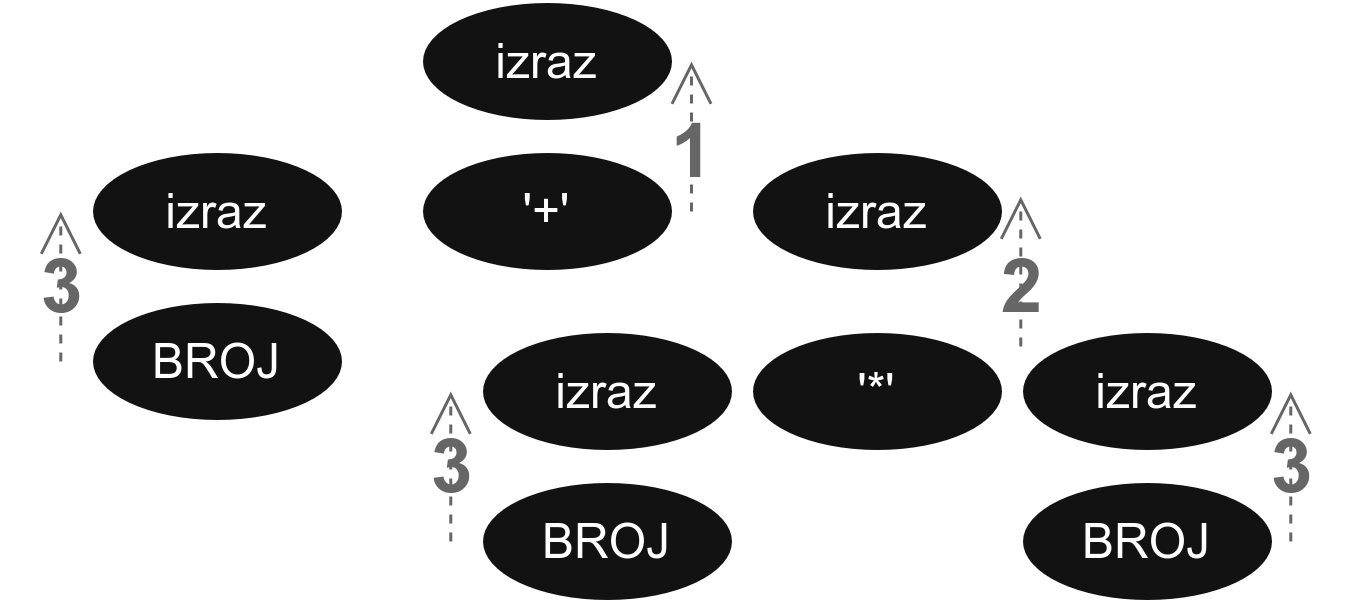
Примећујемо да Bison као да обилази стабло одоздо нагоре. Односно, као да креће од листова стабла и сваки пут када се попне један ниво изнад (што одговара замени десне стране неког правила левом), он примени одговарајућу акцију. Овде деца чворови представљају десне стране правила, а чворови родитељи, леве. И заиста, сваког пута када се иде уз стабло, односно када се од детета пређе на родитеља, као да смо заменили десну страну правила левом и то је тренутак када Bison примењује акцију која одговара том правилу.
Управо ово ће нам бити и важно да искористимо када будемо писали правила за формирање синтаксног стабла јер нам овакав приступ изузетно одговара.
Напомена: Ово је само једно тумачење рада парсера који Bison генерише и служи само за интуитивно схватање редоследа у ком се парсирање одвија. У позадини се користи нешто сложенији потисни аутоматат који је објашњен на предавањима, а прелазима од чворова деце ка родиљима одговара reduce аутомата. Ипак, тачно је да ће се кренути од крајње речи и да заиста можемо на претходно описани начин да доживљавамо како се процес у позадини одвија.
За детаљније објашњење како се тумачење одвија у позадини можете погледати додатак у наредној лекцији.
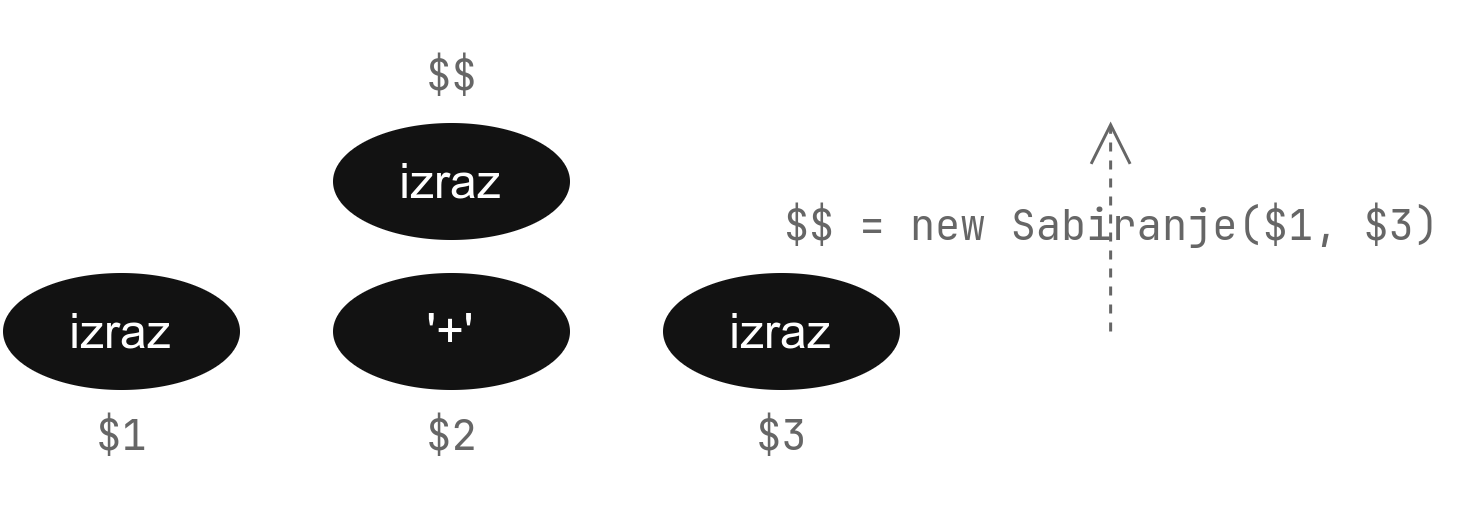
Акције формирања стабла
Имајући на уму претходно, сада врло једноставно можемо да додамо акције које ће креирати синтаксно стабло. На претходном примеру, акције ће изгледати овако:
izraz
: izraz '+' izraz {
$$ = new Sabiranje($1, $3);
}
| izraz '*' izraz {
$$ = new Mnozenje($1, $3);
}
| BROJ {
$$ = new Konstanta($1);
}
;У терминологији претходног објашњења: када се подижемо од чворова деце ка родитељу у стаблу извођења, направимо нови чвор синтаксног стабла одговарајућег типа који зависи од деце.
Чим имамо додавање вредности у акцијама, морамо да спецификујемо ког су типа одговарајући терминали и нетерминали.
То ће бити веома једноставно јер смо направили одговарајућу хијерархију чворова у структури синтаксног стабла.
Прецизније, сви нетерминали који ће чувати чвор синтаксног стабла ће имати тип ASTCvor *, односно, апстрактну класу коју сви остали чворови наслеђују.
Поред њих, терминали ID и BROJ треба да чувају редом ниску (идентификатор) и реалан број, што такође треба да наведемо у парсеру.
Зато у сегмент дефиниција додајемо:
parser.ypp
%union {
double realan_broj;
std::string *niska;
ASTCvor *ast_cvor;
}
%type<ast_cvor> niz_naredbi naredba izrazИ код декларације токена ID и BROJ додајемо типове.
parser.ypp
%token<niska> ID
%token<realan_broj> BROJКако смо доделили токенима типове, то је у лексеру неопходно да поставимо одговарајуће поље променљиве yylval пре враћања одговарајућих токена.
Односно, у lexer.l фајлу треба да изменимо акције које се одвијају при поклапању идентификатора и броја.
lexer.l
{IDENTIFIKATOR} {
yylval.niska = new std::string(yytext);
return ID;
}
{REAL_BROJ} {
yylval.realan_broj = atof(yytext);
return BROJ;
}Сада можемо да попунимо акције, при чему је важно да водимо рачуна о типовима и ослобађању меморије, што је последица тога да углавном радимо са показивачима. Зато је негде потребно прослеђивати показивач, негде га дереференцирати, а негде направити дубоку копију објекта на који он показује. Поред тога, потребно је ослободити заузету меморију свих објекта који нам нису више потребни.
Акције које прате правила за izraz су следеће.
parser.ypp
izraz
: izraz '+' izraz {
$$ = new Sabiranje($1, $3);
}
| izraz '*' izraz {
$$ = new Mnozenje($1, $3);
}
| '-' izraz %prec UMINUS {
$$ = new Negacija($2);
}
| '(' izraz ')' {
$$ = $2;
}
| ID {
$$ = new Promenljiva(*$1);
delete $1;
}
| BROJ {
$$ = new Konstanta($1);
}
;Приметимо да при прављењу чворова синтаксног стабла не ослобађамо меморију чворова деце стабла (не позивамо delete над чворовима стабла).
То радимо зато што желимо да сачувамо све чворове.
Са друге стране, вредност ниске коју чува токен ID нам није потребна онда када се направи чвор синтаксног стабла који чува ту вредност, те ту заузету меморију ослобађамо.
Што се тиче акција уз правила нетерминала naredba, ту исто директно формирамо чворове.
parser.ypp
naredba
: DEF ID '=' izraz ';' {
$$ = new Definicija(*$2, $4);
delete $2;
}
| ID '=' izraz ';' {
$$ = new Dodela(*$1, $3);
delete $1;
}
| PRINT '(' izraz ')' ';' {
$$ = new Ispis($3);
}
| izraz EQ izraz ';' {
$$ = new Poredjenje($1, $3);
}
;Овде такође ослобађамо меморију само за ниске које чувају идентификаторе, јер их чувамо у одговарајућим чворовима синтаксног стабла.
Остаје нам да додамо акције за нетерминал niz_naredbi.
Ту имамо два правила и две акције које треба да додамо.
niz_naredbi
: niz_naredbi naredba {
// akcija 1
}
| naredba {
// akcija 2
}
;Овде нам је циљ да формирамо чвор типа NizNaredbi.
То ћемо радити тако што додајемо наредбу једну по једну.
Међутим, то значи да је редослед наредби важан (јер је важан током извршавања програма), тако да треба да водимо рачуна о томе.
Да бисмо то схватили, посматрајмо парсирање на примеру речи naredba naredba naredba.
Оно би изгледало овако:
naredba naredba naredba
=> niz_naredbi naredba naredba (naredba => niz_naredbi)
=> niz_naredbi naredba (niz_naredbi naredba => niz_naredbi)
=> naredba (niz_naredbi naredba => niz_naredbi)Видимо да ће се наредбе тумачити слева надесно. То се исто може видети цртањем стабла извођења.
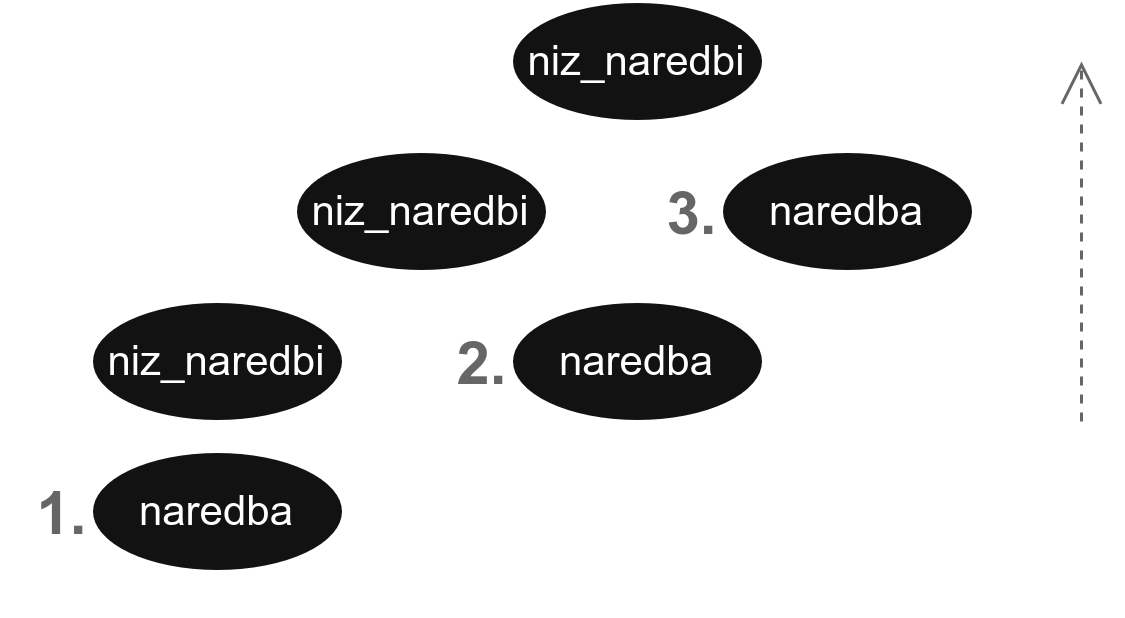
Наиме, видели смо да се парсер креће од листова стабла навише, и видимо да ће се посећивати наредбе слева надесно.
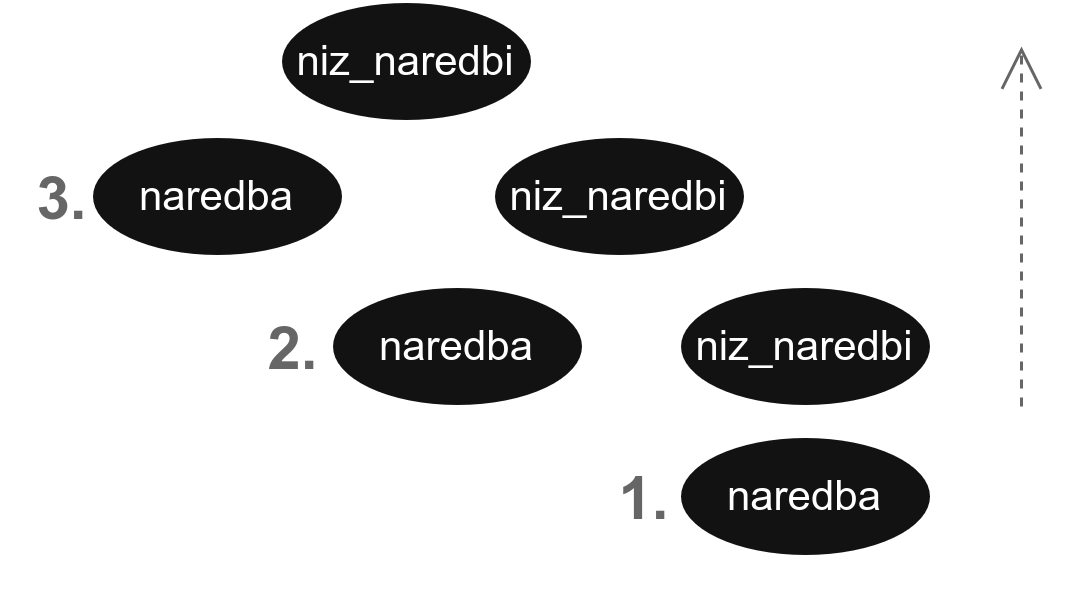
Међутим, да нам је граматика изгледала овако:
niz_naredbi
: naredba niz_naredbi
| naredba
;Извођење би изледало овако:
naredba naredba naredba
=> naredba naredba niz_naredbi (naredba => niz_naredbi)
=> naredba niz_naredbi (naredba niz_naredbi => niz_naredbi)
=> naredba (naredba niz_naredbi => niz_naredbi)Односно, обилазили бисмо наредбе у супротном редоследу, што опет можемо да видимо и из стабла извођења.
Вратимо се назад на акције које треба да попунимо.
Оно што желимо је да при парсирању прве наредбе направимо објекат класе NizNaredbi, и да сваку нову наредбу додајемо у тај објекат.
Из претходног закључујемо да прво мора да се иврши акција број 2 (јер она одговара првом листу стабла извођења), а онда ће за све остале наредбе бити извршавана акција број 1.
Дакле, акција 2 треба да креира нови чвор синтаксног стабла, а акција 1 да у исти тај чвор додаје нову наредбу.
Сходно томе, акције треба да изледају овако:
parser.ypp
niz_naredbi
: niz_naredbi naredba {
// akcija 1
NizNaredbi *niz_naredbi = dynamic_cast<NizNaredbi *>($1);
niz_naredbi->dodaj_cvor($2);
$$ = niz_naredbi;
}
| naredba {
// akcija 2
NizNaredbi *niz_naredbi = new NizNaredbi();
niz_naredbi->dodaj_cvor($1);
$$ = niz_naredbi;
}
;Разлог зашто је неопходно користити dynamic_cast је што је нетерминал niz_naredbi (коме приступамо помоћу $1) типа ASTCvor *.
Међутим, нама је потребан метод dodaj_cvor који класа ASTCvor не поседује.
Зато прво кастујемо чвор у објекат типа NizNaredbi и даље настављамо рад са тим објектом.
Да бисмо коначно сачували цело стабло извођења, додајмо једну глобалну променљиву у сегменту дефиниција.
parser.ypp
%{
ASTCvor *ast = nullptr;
%}И у акцији за аксиому додајемо:
parser.ypp
program
: niz_naredbi {
ast = $1;
}
;За Bison пројекте који су само интерпретирали или парсирали изворне фајлове, у граматици често нисмо имали правило типа
program: niz_naredbi ;. Оно не мења језик који граматика одређује и није нам било потребно. Међутим, када желимо да направимо синтаксно стабло, такво правило ће нам бити неопходно да бисмо на крају приступили корену синтаксног стабла које се формира у осталим правилима.
Повезивање
На крају остаје да само у сегменту корисничког кода помоћу објекта ast приступимо формираном синтаксном стаблу и позивамо методе које желимо, нпр. за испис стабла и његову интерпретацију.
Не заборавимо да треба да позовемо деструктор!
parser.ypp
int main() {
if (yyparse() == 0) {
std::cout << "prihvaceno" << std::endl;
}
// ispis
std::cout << *ast << std::endl;
// interpretacija
TabelaSimbola tabela_simbola;
ast->interpretiraj(tabela_simbola);
delete ast;
// pozivamo desktuktor za lekser
yylex_destroy();
return 0;
}Да би се све превело потребно је у Makefile додати команде за превођење фајлова за синтаксно стабло и табелу симбола.
Makefile
CC = g++
CFLAGS = -Wall -Wextra
parser: lex.yy.o parser.tab.o sintaksno_stablo.o tabela_simbola.o
$(CC) $(CFLAGS) $^ -o $@
lex.yy.o: lex.yy.c parser.tab.hpp
$(CC) $(CFLAGS) -c $< -o $@
lex.yy.c: lexer.l parser.tab.hpp
flex --nounput $<
parser.tab.o: parser.tab.cpp parser.tab.hpp
$(CC) $(CFLAGS) -c $< -o $@
parser.tab.cpp parser.tab.hpp: parser.ypp sintaksno_stablo.hpp tabela_simbola.hpp
bison --header $<
sintaksno_stablo.o: sintaksno_stablo.cpp sintaksno_stablo.hpp
$(CC) $(CFLAGS) -c $< -o $@
tabela_simbola.o: tabela_simbola.cpp tabela_simbola.hpp
$(CC) $(CFLAGS) -c $< -o $@
.PHONY: clean
clean:
rm -f *.o parser.tab.* lex.yy.c parserПреведимо пројекат.
$ make
bison --header parser.ypp
flex --nounput lexer.l
g++ -Wall -Wextra -c lex.yy.c -o lex.yy.o
g++ -Wall -Wextra -c parser.tab.cpp -o parser.tab.o
g++ -Wall -Wextra -c sintaksno_stablo.cpp -o sintaksno_stablo.o
sintaksno_stablo.cpp: In member function ‘virtual double Konstanta::interpretiraj(TabelaSimbola&) const’:
sintaksno_stablo.cpp:290:48: warning: unused parameter ‘tabela_simbola’ [-Wunused-parameter]
290 | double Konstanta::interpretiraj(TabelaSimbola &tabela_simbola) const {
| ~~~~~~~~~~~~~~~^~~~~~~~~~~~~~
g++ -Wall -Wextra -c tabela_simbola.cpp -o tabela_simbola.o
g++ -Wall -Wextra lex.yy.o parser.tab.o sintaksno_stablo.o tabela_simbola.o -o parserДобијамо упозорење да у дефиницији методе
Konstanta::interpretirajнисмо искористили параметарtabela_simbola. Међутим, то је оно што и желимо, тако да игноришемо ово упозорење.
И покренимо.
$ ./parser < test
prihvaceno
def x = 2.5;
x = ((x) * (x)) + (2);
print(- (x));
(16.5) == ((2) * (x));
-8.25
TrueПрви део је испис синтаксног стабла, а други резултат његовог извршавања. Дакле, заиста смо формирали синтаксно стабло за задати програм, чиме смо комплетирали синтаксичку анализу.
Претходно: Синтаксна стабла
Следеће: Пример језика за рад са функцијама
Додатак (генерисање кода)
Сада смо прошли комплетно кроз лексичку и синтаксичку анализу. Међутим, било би занимљиво када бисмо наставили тај процес и отишли у даље фазе. Оно што је помало неочекивано је да, иако смо обрадили само прве две фазе процеса компилације, помоћу синтаксног стабла програма, превођење на машински код (асемблер) није толико компликовано (бар за једноставне језике).
Оно што је комликовано, и разлог зашто постоји више каснијих фаза, је генерисати машински код који је употребљив тј. који ће се извршавати у разумном времену. Још теже од тога је генерисати машински код који би се што оптималније извршавао. То је задатак за остале фазе и извор многих модерних области истраживања у области компилација.
Зато ћемо сада у потпуности занемарити перформансе и покушати да урадимо фазу генерисања кода.
Дакле, улаз нам је неки програм написан на језику са којим смо радили до сада, а излаз желимо да буде фајл на једноставном асемблеру. Особине тог асемблера су следеће:
- на располагању имамо неограничен број регистара са именима
r0,r1,r2итд. - доступне су наредне инструкције:
mov op1, op2која у регистарop1поставља вредност константе или регистраop2store op1, [op2]која вредност у региструop1чува у меморију на адресу на која одговара променљивој у програмуop2(инструкције попутstore r3, [x], где јеxнека променљива у програму за коју подразумевамо да је меморија унапред алоцирана)load op1, [op2]која у регистарop1чува вредност која је у меморији на адреси која одговара променљивој у прогамуop2add op1, op2која сабира два регистра и резултат чува у региструop1mul op1, op2која множи два регистра и резултат чува у региструop1neg op1која негира вредност у региструop1cmp op1, op2која пореди два регистра на једнакост и уписује резултат поређења у flag регистарjmp labelaкоја прелази на део означен лабеломlabelaje labelaкоја прелази на део означен лабеломlabelaуколико је постављен бит за једнакост у flag региструcall printкоја позива функцијуprintса аргументом који се налази у региструr0
Да бисмо од синтаксног стабла генерисасли код на оваквом асемблеру, биће неопходно да сваки чвор стабла поседује методу prevedi који ће га преводити у асемблер.
To значи да у потпису класе ASTCvor треба да додамо још једну чисто виртуелну методу prevedi.
Препорука: Ово је моменат где можете да покушате сами да урадите задатак. Дакле, треба допунити све класе синтаксног стабла новом методом за превођење на описани асемблер.
Једно решење је да то урадимо на следећи начин:
sintaksno_stablo.hpp
class ASTCvor {
public:
virtual ~ASTCvor();
virtual void ispisi(std::ostream &os) const = 0;
virtual double interpretiraj(TabelaSimbola &tabela_simbola) const = 0;
virtual int prevedi(std::ofstream &fajl) const = 0;
virtual ASTCvor *kloniraj() const = 0;
};Параметар ове функције је типа std::ofstream & да бисмо уписивали резултат у фајл.
То је само C++ начин за рад са фајловима (као да смо у C-у користили FILE *).
Упис у фајл ће бити сличан испису на стандардни излаз тј. биће облика fajl << "mov r0, r1"
Повратна вредност је важнија и одабрана је да буде типа int.
Идеја је да тај цео број представља индекс регистра у који ће бити сачуван резултат чвора.
На пример, за превођење чвора типа Sabiranje биће неопходно да
- преведемо оба његова детета,
m_leviиm_desni - саберемо њихове резултате инструкцијом
add ri, rjгде је у региструriсачуван резултат левог сабирака, а у региструrjрезултат десног.
Због другог корака биће нам лакше ако би сама метода prevedi враћала бројеве i и j.
Код методе
interpretirajсмо изабрали да јој повратна вредност буде тип израза са којима програмски језик ради, што је било смислено само за чворове који рачунају вредност израза, док смо за остале чворове враћали неку неважну вредност. Слично и овде, повратна вредност методеprevediће бити вредност регистра што има смисла само за чворове који врше неко израчунавње, попутSaberi, док ће за остале враћати неку неважну константу (за чворове попутDodela).
Осим имплементације метода, биће неопходно да се он и декларише у свим класама.
Прецизније, у фајлу sintaksno_stablo.hpp, у оквиру декларација свих конкретних (неапстрактних) класа (тј. свих класа осим UnarniCvor и BinarniCvor), треба додати следеће:
sintaksno_stablo.hpp
int prevedi(std::ofstream &fajl) const override;Док у апстрактним класама (тј. у класама UnarniCvor и BinarniCvor) опцино можемо додати декларацију чисто виртуелне методе prevedi.
sintaksno_stablo.hpp
virtual int prevedi(std::ofstream &fajl) const = 0;Сада је неопходно да имплементирамо ову методу у свим конкретним класама синтаксног стабла.
Класа NizNaredbi
За ову класу превођење се своди на позив метода за превођење за све наредбе редом. Опционо исписујемо нови ред након превођења сваке наредбе да бисмо лакше читали касније асемблер.
sintaksno_stablo.cpp
int NizNaredbi::prevedi(std::ofstream &fajl) const {
for (ASTCvor *cvor : m_naredbe) {
cvor->prevedi(fajl);
fajl << "\n";
}
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return 0;
}Класе Definicija и Dodela
Ово је превођење наредби типа def x = 2.5; и x = 2.5;.
У оба случаја, потребно je:
- превести израз
m_izrazи његов резултат сачувати у регистар (примера ради, нека будеr5) - сачувати вредност у том регистру на меморију која је додељена променљивој
m_id(у овом примеру, то би билоx)
Тако да би асемблер за наредбу def x = 2.5; био:
mov r5, 2.5
store r5, [x]У имплементацији, број регистра ћемо добити као повратну вредност превођења израза, што може да се уради на следећи начин:
sintaksno_stablo.cpp
int Definicija::prevedi(std::ofstream &fajl) const {
int izraz_registar = m_izraz->prevedi(fajl);
fajl << "store r" << izraz_registar << ", [" << m_id << "]\n";
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return 0;
}
int Dodela::prevedi(std::ofstream &fajl) const {
int izraz_registar = m_izraz->prevedi(fajl);
fajl << "store r" << izraz_registar << ", [" << m_id << "]\n";
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return 0;
}Класа Promenljiva
Ово је чвор који треба да враћа вредност променљиве чији идентификатор чува.
Зато је овде потребно само учитати вредност из меморије која одговара променљивој са идентификатором m_id и ставити је у неки слободан регистар.
Односно, овакви чворови ће се превести у једну инструкцију
load ri, [m_id]Главни проблем овде је наћи регистар ri који није већ заузет.
Међутим, у нашем асемблеру се тај проблем лако решава јер имамо неограничено много регистара, па ћемо да уведемо глобалну променљиву indeks_slobodnog_registra која ће чувати први неискоришћен регистар.
Биће иницијализована на 1 (јер је r0 регистар из ког чита функција print), а сваки пут када искористимо регистар на који она показује повећаћемо је за 1.
Како је имплементација нашег стабла у два фајла (sintaksno_stablo.hpp и sintaksno_stablo.cpp), то ћемо у фајлу заглавља да декларишемо ту глобалну променљиву.
sintaksno_stablo.hpp
extern int indeks_slobodnog_registra;Док ћемо у изворном фајлу да је дефинишемо (поставимо јој вредност на 1).
sintaksno_stablo.cpp
int indeks_slobodnog_registra = 1;Сада се имплеметација метода за превођење може урадити на следећи начин:
sintaksno_stablo.cpp
int Promenljiva::prevedi(std::ofstream &fajl) const {
int registar = indeks_slobodnog_registra;
indeks_slobodnog_registra++;
fajl << "load r" << registar << ", [" << m_id << "]\n";
return registar;
}Класа Konstanta
Слично као и класи Promenljiva, овде само треба поставити вредност коју чува објекат ове класе у слободан регистар.
То ћемо опет да урадимо коришћењем променљиве indeks_slobodnog_registra, а уместо load инструкције, овде ће нам бити потребна mov интрукција.
sintaksno_stablo.cpp
int Konstanta::prevedi(std::ofstream &fajl) const {
int registar = indeks_slobodnog_registra;
indeks_slobodnog_registra++;
fajl << "mov r" << registar << ", " << m_vrednost << "\n";
return registar;
}Класа Negacija
Овде треба израчунати вредност израза m_izraz, негарати регистар у који је он сачуван и вратити га.
sintaksno_stablo.cpp
int Negacija::prevedi(std::ofstream &fajl) const {
int izraz_registar = m_cvor->prevedi(fajl);
fajl << "neg r" << izraz_registar << "\n";
return izraz_registar;
}Класа Ispis
Овде након рачунања вредности израза m_izraz, треба поставити ту вредност у регистар r0 и онда позвати функцију print (у опису асемблера је дато да print исписује на стандардни излаз вредност у регистру r0).
sintaksno_stablo.cpp
int Ispis::prevedi(std::ofstream &fajl) const {
int izraz_registar = m_cvor->prevedi(fajl);
fajl << "mov r0, r" << izraz_registar << "\n";
fajl << "call print\n";
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return 0;
}Наредне две класе наслеђују BinarniCvor и њихово превођење ће бити веома слично.
У обе треба израчунати вредности левог и десног подизраза, и онда сабрати вредности регистара у којима су оне сачуване.
Класа Sabiranje
sintaksno_stablo.cpp
int Sabiranje::prevedi(std::ofstream &fajl) const {
int levi_registar = m_levi->prevedi(fajl);
int desni_registar = m_desni->prevedi(fajl);
fajl << "add r" << levi_registar << ", r" << desni_registar << "\n";
return levi_registar;
}Класа Mnozenje
sintaksno_stablo.cpp
int Mnozenje::prevedi(std::ofstream &fajl) const {
int levi_registar = m_levi->prevedi(fajl);
int desni_registar = m_desni->prevedi(fajl);
fajl << "mul r" << levi_registar << ", r" << desni_registar << "\n";
return levi_registar;
}Класа Poredjenje
Покушајмо да преведемо наредбу x == y; у асемблер.
То би изгледало некако овако:
load r1, [x]
load r2, [y]
cmp r1, r2
je jednako_labela
mov r0, 0
jmp kraj_labela
jednako_labela:
mov r0, 1
kraj_labela:
call printПрво учитамо вредности које одговарају x и y у слободне регистре.
Затим их упоредимо и, у зависности од резултата поређења, у регистар r0 уписујемо 0 или 1 (који редом представљају False, односно True).
На крају позивамо функцију print за испис на стандардни излаз.
То можемо да имплементирамо на следећи начин:
sintaksno_stablo.cpp
int Poredjenje::prevedi(std::ofstream &fajl) const {
int levi_registar = m_levi->prevedi(fajl);
int desni_registar = m_desni->prevedi(fajl);
fajl << "cmp r" << levi_registar << ", r" << desni_registar << "\n";
fajl << "je jednako_labela\n";
fajl << "mov r0, 0\n";
fajl << "jmp kraj_labela\n";
fajl << "jednako_labela:\n";
fajl << "mov r0, 1\n";
fajl << "kraj_labela:\n";
fajl << "call print\n";
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return 0;
}Међутим, може да настане проблем ако у програму имамо више наредби поређења.
Наиме, ако бисмо након овог, имали још једно поређење, за њега бисмо генерисали асемблер који би користио исте лабеле.
То би изазвало неочекивано понашање у асемблерском коду, јер би jmp инструкције скакале на места која нису везана за то поређење, већ претходно.
То значи да би било потребно да за свако ново поређење дајемо нова имена лабелама.
То ћемо решити слично као и проблем слободних регистара.
Све лабеле ћемо означавати редом са labela0, labela1, labela2 итд.
Ради праћења слободне лабеле увешћемо глобалну променљиву indeks_slobodne_labele која ће бити иницијализована на 0 и при сваком њеном коришћењу ћемо је увећавати за 1.
Дакле, додаћемо наредне две линије у одговарајуће фајлове.
sintaksno_stablo.hpp
extern int indeks_slobodne_labele;sintaksno_stablo.cpp
int indeks_slobodne_labele = 0;Сада можемо да преправимо имплементацију.
sintaksno_stablo.cpp
int Poredjenje::prevedi(std::ofstream &fajl) const {
int levi_registar = m_levi->prevedi(fajl);
int desni_registar = m_desni->prevedi(fajl);
fajl << "cmp r" << levi_registar << ", r" << desni_registar << "\n";
int jednako_labela = indeks_slobodne_labele;
indeks_slobodne_labele++;
int kraj_labela = indeks_slobodne_labele;
indeks_slobodne_labele++;
fajl << "je label" << jednako_labela << "\n";
fajl << "mov r0, 0\n";
fajl << "jmp label" << kraj_labela << "\n";
fajl << "label" << jednako_labela << ":\n";
fajl << "mov r0, 1\n";
fajl << "label" << kraj_labela << ":\n";
fajl << "call print\n";
// vracamo neku vrednost samo da bismo
// se uskladili sa definicijom metoda
return 0;
}Тестирање
То је било све што је потребно да бисмо генерисали код на овако занимшљеном асемблеру.
Да бисмо га испробали, потрбено је да у сегменту корисничког кода у main функцији, додамо:
parser.ypp
// prevodjenje
std::ofstream fajl("program.asm");
ast->prevedi(fajl);
fajl.close();Дакле, правимо нови фајл program.asm, онда над направљеним синтаксним стаблом позивамо метод за превођење, и затварамо фајл.
Преведимо пројекат и тестирајмо га на примеру који смо ставили у фајл test.
test
def x = 2.5;
x = x * x + 2;
print(- x);
16.5 == 2 * x;Покретањем
$ ./parser < testдобијамо нови фајл program.asm са наредним садржајем.
program.asm
mov r1, 2.5
store r1, [x]
load r2, [x]
load r3, [x]
mul r2, r3
mov r4, 2
add r2, r4
store r2, [x]
load r5, [x]
neg r5
mov r0, r5
call print
mov r6, 16.5
mov r7, 2
load r8, [x]
mul r7, r8
cmp r6, r7
je label0
mov r0, 0
jmp label1
label0:
mov r0, 1
label1:
call printЈасно можемо да видимо које инструкције се односе на које наредбе и можемо да се уверимо да превођење заиста ради. Дакле, успешно смо превели произвољан изворни фајл на нашем замишљеном програмском језику на асемблер – направили смо компајлер!
Недостаци
Ипак, није све тако идеално. Као што је већ речено, лакши део посла је генерисати код. Тежи је генерисати употребљив код.
То се може видети и на претходном примеру, али покушајмо да будемо експлицитнији.
Наредни део кода
y = x + x;
print(x);ће се превести у
program.asm
load r1, [x]
load r2, [x]
add r1, r2
store r1, [y]
load r3, [x]
mov r0, r3
call printПриметимо да овде три пута приступамо меморији да бисмо добили вредност променљиве x, иако би овде било довољно то урадити само једном.
Овако једноставан пример може се извршавати за ред величине спорије него оптималан код (звог вишеструког непотребног приступа меморији).
Ако бисмо користили наш компајлер за неке сложеније случајеве, добијени програм заиста не би био употребљив.
Дакле, овде би решење било да користимо исте регистре више пута. Међутим, непотребан приступ меморији није једини разлог зашто код може бити спорији (може се десити да нпр. имамо и нека непотребна израчунавања). Ово никако није крај посла и потребно је увести додатну логику – додати оптимизације генерисаном коду.
Управо је то главни задатак даљих фаза компилације и циљ ове дигресије био је да се да мотивација за њихово постојање.
-
Уместо
--header, може се користити и опција-dкоја исто генерише фајл заглавља. Једина разлика је у томе што сеheaderопцијом може задати и име тог генерисаног фајла помоћу--header=FILE. ↩