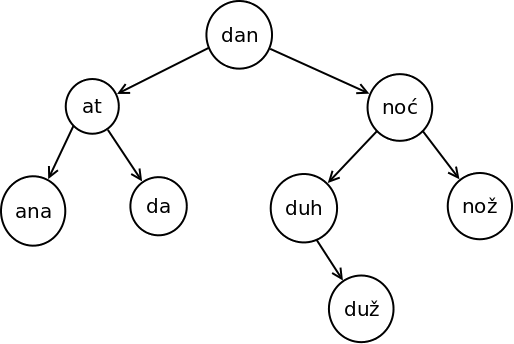
Primer 1.1.1. Na slici 1 prikazano je uređeno binarno drvo koje sadrži niske ana, at, noć, nož, da, dan, duh i duž kao ključeve.
Struktura podataka sa asocijativnim pristupom (skup, mapa tj. rečnik), kod koje se pristup elementima vrši po ključu, efikasno se implementira korišćenjem uređenog binarnog drveta ili heš-tabele1. Ključ ne mora biti celobrojna vrednost, već niska karaktera, niska bitova ili nešto drugo.
Primer 1.1.1. Na slici 1 prikazano je uređeno binarno drvo koje sadrži niske ana, at, noć, nož, da, dan, duh i duž kao ključeve.
Prilikom svih operacija sa uređenim binarnim drvetom (pretraga, brisanje, umetanje) u svakom čvoru se vrši poređenje ključeva (onog koji je zapisan u čvoru i onog koji se obrađuje) i kada su ključevi niske (ali i neki drugi veći podaci), to poređenje može zahtevati dosta vremena i loše uticati na performanse.
Još jedna struktura podataka u vidu drveta koja omogućava efikasan asocijativni pristup kada su ključevi niske je prefiksno drvo (engl. prefix tree), takođe poznato pod engleskim nazivom trie (od engleske reči reTRIEval).
Problem. Definisati asocijativnu strukturu podataka koja omogućava interfejs skupa/mape (dodavanje, traženje i brisanje elemenata) u kojoj su ključevi niske ili nizovi, a koja podržava i efikasno pronalaženje svih elemenata čiji ključevi imaju zadati prefiks.
Osnovna ideja ove strukture podataka je da se ključ pridružen čvoru dobija nadovezivanjem karaktera koji se nalaze na granama duž putanje od korena do tog čvora. Koren sadrži praznu reč, a prelaskom preko grane se na do tada formiranu reč zdesna nadovezuje još jedan karakter, pa svakom čvoru odgovara neki prefiks ključa. Pritom, zajednički prefiksi različitih ključeva su predstavljeni istim putanjama od korena do tačke razlikovanja (čvora koji odgovara najdužem zajedničkom prefiksu). Čvorovi prefiksnog drveta mogu imati različit broj dece, ali maksimalni broj dece određen je veličinom azbuke koja se koristi za kodiranje ključeva. Ako se pomoću prefiksnog drveta implementira mapa (rečnik), tada se svakom ključu pridružuje vrednost (podatak koji se čuva u čvoru drveta kojim se kompletira taj ključ).
Primer 1.1.2. Jedan primer prefiksnog drveta dat je na slici 2.
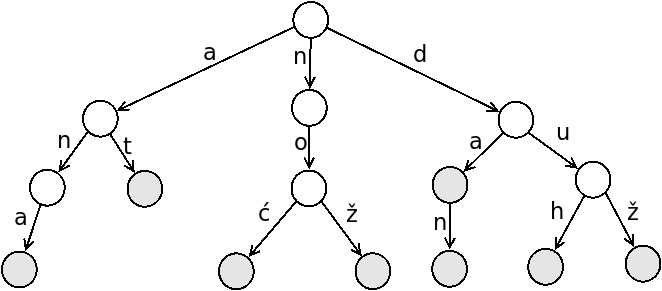
Ključevi koje ovo prefiksno drvo čuva su isti oni koje čuva uređeno binarno drvo sa slike 1: ana, at, noć, nož, da, dan, duh i duž (bez pridruženih podataka). Većina ključeva koje prefiksno drvo u ovom primeru čuva se završava u nekom od listova. Međutim, to u opštem slučaju ne mora da važi: ključ da se ne završava u listu. Stoga je potrebno da svaki čvor prefiksnog drveta čuva i informaciju o tome da li se njime kompletira neki ključ ili ne (što se lako implementira dodavanjem odgovarajuće logičke promenljive u čvor drveta). Na slici 2 čvorovi kojima se kompletira neki ključ su obojeni.
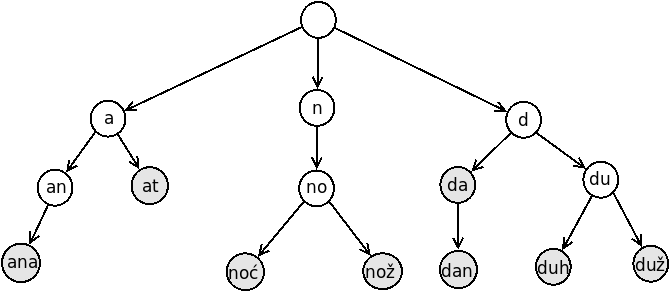
Ilustracije radi, na slici 3 uz čvorove prefiksnog drveta predstavljenog na slici 2 prikazane su oznake akumulirane do tih čvorova. Treba imati u vidu da se prikazani prefiksi dobijeni nadovezivanjem karaktera duž grana do svakog čvora ne čuvaju eksplicitno u čvoru.
U narednom apletu možete isprobati kako se reči ubacuju u prefiksno drvo.
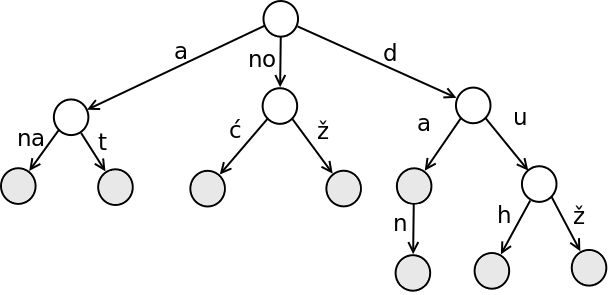
Mana prefiksnog drveta može biti to što uz podatke koje čuva zauzima i puno dodatne memorije (za čuvanje pokazivača) i stoga je poželjno komprimovati ga. Ako neki čvor ima samo jednog potomka i ne predstavlja kraj nekog ključa, grana do njega i grana od njega se mogu spojiti u jednu, njihovi karakteri nadovezati, a čvor eliminisati. Ovako se dobija kompaktnija reprezentacija prefiksnog drveta kod koje svaki unutrašnji čvor ima bar dva deteta (slika 4), pri čemu grane mogu biti označene niskama, a ne samo pojedinačnim karakterima.
Pored toga toga što se prefiksnim drvetom mogu implementirati opšte asocijativne strukture kao skup i mapa, prefiksnim drvetom može se implementirati i konačni rečnik koji omogućava automatsko kompletiranje ili proveru ispravnosti, odnosno automatsko ispravljanje reči koje korisnik unosi na računaru ili mobilnom telefonu.
Ključevi u prefiksnom drvetu ne moraju biti isključivo niske karaktera. Na primer, u prefiksnom drvetu možemo čuvati i ključeve koji su prirodni brojevi, pri čemu se tada koristi niz cifara u njihovom dekadnom ili binarnom zapisu. Pored niski, najčešće se koriste binarne reprezentacije brojeva fiksne širine (zapisanih sa fiksnim brojem binarnih cifara).
Operacije traženja i umetanja elemenata u prefiksno drvo vrše se na prilično očigledan način, dok je u slučaju brisanja nekada potrebno brisati više od jednog čvora.
Ispitivanje da li se neka reč nalazi u prefiksnom drvetu može se realizovati rekurzivnom funkcijom koja kao argumente dobija koren drveta i reč koju traži u drvetu (tokom rekurzivnih poziva u pitanju je koren odgovarajućeg poddrveta prefiksnog drveta i neki sufiks reči koja se pretražuje). Ako je reč prazna, ona se nalazi u drvetu ako i samo ako je koren obeležen kao kraj ključa. Ako reč nije prazna, da bi se ona mogla nalaziti u drvetu potrebno je da postoji dete korena do kog se stiže preko njenog prvog slova i tada pretragu nastavljamo rekurzivno od tog čvora za sufiks reči bez tog prvog slova.
I operaciju umetanja reči u prefiksno drvo možemo implementirati kao rekurzivnu funkciju koja kao argumente dobija koren drveta i reč koju treba ubaciti u to drvo. Ako je reč prazna, obeležavamo da se u korenu nalazi kraj reči. U suprotnom proveravamo da li postoji dete korena do kog se stiže prvim slovom te reči i ako ne postoji dodajemo ga. Zatim rekurzivno nastavljamo umetanje od tog čvora i umećemo sufiks reči bez tog prvog slova.
U nastavku su date implementacije osnovnih operacija nad prefiksnim drvetom na primeru formiranja i pretrage skupa reči na engleskom jeziku. U ovom primeru ključevi su reči (niske karaktera) i nisu im pridružene nikakve vrednosti. Potrebno je podržati operaciju dodavanja ključeva u strukturu podataka i provere da li ključ postoji u strukturi. Čvor prefiksnog drveta može se definisati tako da sadrži niz pokazivača, čijim elementima odgovaraju svi mogući karakteri azbuke iz koje se formiraju ključevi (npr. pošto se u ovom primeru kodiraju samo reči koje se sastoje od malih slova engleske abecede, možemo koristiti niz pokazivača dužine 26). Međutim, efikasnije je u svakom čvoru čuvati informacije samo o onim karakterima za koje postoji grana iz tog čvora, odnosno u ove svrhe iskoristiti mape. Dakle, u svakom čvoru prefiksnog drveta čuvamo neuređenu (heš) mapu koja karakterima pridružuje grane koje kreću iz tog čvora ka njegovoj deci, pri čemu koristimo bibliotečku implementaciju heš-mape (klasu unordered_map deklarisanu u istoimenom zaglavlju). Operacije umetanja i pretrage se mogu jednostavno implementirati bilo rekurzivno bilo iterativno (u nastavku je prikazana rekurzivna implementacija).
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
// osnovna struktura čvora prefiksnog drveta - u svakom čvoru čuvamo mapu
// koja karakterima pridružuje pokazivače ka potomcima kao i informaciju
// o tome da li je u čvoru kraj neke reči
struct cvor {
bool krajKljuca = false;
unordered_map<char, cvor*> grane;
};
// sufiks koji počinje na poziciji i reči w tražimo
// u drvetu na čiji koren ukazuje pokazivač drvo
bool nadji(cvor *drvo, const string& w, int i) {
// ako je sufiks prazan, on je u korenu akko je u korenu obeleženo
// da je tu kraj reči
if (i == w.size())
return drvo->krajKljuca;
// tražimo granu na kojoj piše w[i]
auto it = drvo->grane.find(w[i]);
// ako je nađemo, rekurzivno tražimo ostatak sufiksa od pozicije i+1
if (it != drvo->grane.end())
return nadji(it->second, w, i+1);
// nismo našli granu sa w[i], pa reč ne postoji
return false;
}
// tražimo reč w u drvetu na čiji koren ukazuje pokazivač drvo
bool nadji(cvor *drvo, const string& w) {
return nadji(drvo, w, 0);
}
// umetanje sufiksa koji počinje na poziciji i reči w
// u drvo na čiji koren ukazuje pokazivač drvo
void umetni(cvor *drvo, const string& w, int i) {
// ako je sufiks prazan samo u korenu beležimo da je tu kraj reči
if (i == w.size()) {
drvo->krajKljuca = true;
return;
}
// tražimo granu na kojoj piše w[i]
auto it = drvo->grane.find(w[i]);
// ako takva grana ne postoji, dodajemo je kreirajući novi čvor
if (it == drvo->grane.end())
drvo->grane[w[i]] = new cvor();
// sada znamo da grana sa w[i] sigurno postoji i preko te grane
// nastavljamo dodavanje sufiksa koji počinje na poziciji i+1
umetni(drvo->grane[w[i]], w, i+1);
}
// umetanje reči w u drvo na čiji koren ukazuje pokazivač drvo
void umetni(cvor *drvo, string& w) {
return umetni(drvo, w, 0);
}
// brisanje drveta sa korenom u čvoru drvo
void obrisi(cvor *drvo) {
if (drvo != nullptr) {
for (const auto& p : drvo->grane)
obrisi(p.second);
delete drvo;
}
}#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
// osnovna struktura čvora prefiksnog drveta - u svakom čvoru čuvamo mapu
// koja karakterima pridružuje pokazivače ka potomcima kao i informaciju
// o tome da li je u čvoru kraj neke reči
struct cvor {
bool krajKljuca = false;
unordered_map<char, cvor*> grane;
};
// sufiks koji počinje na poziciji i reči w tražimo
// u drvetu na čiji koren ukazuje pokazivač drvo
bool nadji(cvor *drvo, const string& w, int i) {
// ako je sufiks prazan, on je u korenu akko je u korenu obeleženo
// da je tu kraj reči
if (i == w.size())
return drvo->krajKljuca;
// tražimo granu na kojoj piše w[i]
auto it = drvo->grane.find(w[i]);
// ako je nađemo, rekurzivno tražimo ostatak sufiksa od pozicije i+1
if (it != drvo->grane.end())
return nadji(it->second, w, i+1);
// nismo našli granu sa w[i], pa reč ne postoji
return false;
}
// tražimo reč w u drvetu na čiji koren ukazuje pokazivač drvo
bool nadji(cvor *drvo, const string& w) {
return nadji(drvo, w, 0);
}
// umetanje sufiksa koji počinje na poziciji i reči w
// u drvo na čiji koren ukazuje pokazivač drvo
void umetni(cvor *drvo, const string& w, int i) {
// ako je sufiks prazan samo u korenu beležimo da je tu kraj reči
if (i == w.size()) {
drvo->krajKljuca = true;
return;
}
// tražimo granu na kojoj piše w[i]
auto it = drvo->grane.find(w[i]);
// ako takva grana ne postoji, dodajemo je kreirajući novi čvor
if (it == drvo->grane.end())
drvo->grane[w[i]] = new cvor();
// sada znamo da grana sa w[i] sigurno postoji i preko te grane
// nastavljamo dodavanje sufiksa koji počinje na poziciji i+1
umetni(drvo->grane[w[i]], w, i+1);
}
// umetanje reči w u drvo na čiji koren ukazuje pokazivač drvo
void umetni(cvor *drvo, string& w) {
return umetni(drvo, w, 0);
}
// brisanje drveta sa korenom u čvoru drvo
void obrisi(cvor *drvo) {
if (drvo != nullptr) {
for (const auto& p : drvo->grane)
obrisi(p.second);
delete drvo;
}
}
int main() {
// prefiksno drvo u kom cuvamo skup reci
cvor* drvo = new cvor();
// ucitavamo skup od n reci
int n;
cin >> n;
for (int i = 0; i < n; i++) {
string w;
cin >> w;
umetni(drvo, w);
}
// za narednih m reci proveravamo da li pripadaju skupu
int m;
cin >> m;
for (int i = 0; i < m; i++) {
string w;
cin >> w;
cout << w << ": " << (nadji(drvo, w) ? "da" : "ne") << endl;
}
// brisemo drvo
obrisi(drvo);
}Prethodne funkcije možemo testirati sledećim programom: u njemu se najpre neke reči ubacuju u prefiksno drvo, a zatim se za te reči i neke druge reči proverava da li se nalaze u drvetu. Za reči koje se nalaze u drvetu program ispisuje da, dok za reči koje se u njemu ne nalaze ispisuje ne.
// program kojim testiramo gornje funkcije
int main() {
cvor* drvo = new cvor();
vector<string> reci
{"ana", "at", "noc", "noz", "da", "dan", "duh", "duz"};
vector<string> reci_neg
{"", "a", "d", "ananas", "marko", "ptica"};
for (auto w : reci)
umetni(drvo, w);
for (const string& w : reci)
cout << w << ": " << (nadji(drvo, w) ? "da" : "ne") << endl;
for (const string& w : reci_neg)
cout << w << ": " << (nadji(drvo, w) ? "da" : "ne") << endl;
obrisi(drvo);
return 0;
}Kada azbuka kojom se kodiraju ključevi ima \(K\) elemenata i kada se u svakom čvoru čuva neuređena mapa grana, složenost operacija pretraživanja, umetanja i brisanja elementa iz prefiksnog drveta je u najgorem slučaju \(O(mK)\), gde je \(m\) dužina reči koja se traži, umeće ili briše. Zaista, složenost najgoreg slučaja pretrage neuređene mape je \(O(K)\), a prilikom obrade ključa dužine \(m\) vrši se \(m\) takvih pretraga. Sa druge strane, amortizovana složenost pretrage neuređene mape je \(O(1)\), pa je amortizovana složenost ovih operacija \(O(m)\). Ako se radi sa niskama karaktera i ako se neuređena mapa implementira pomoću niza od \(K\) elemenata, onda je i složenost najgoreg slučaja \(O(m)\). Primetimo da je prilikom pretrage broj operacija ograničen i dužinama reči koje se nalaze u drvetu, pa se, preciznije, složenost može ograničiti i sa \(O(\min(m, M))\), gde je \(M\) dužina najduže reči kojia se nalazi u drvetu.
Dobra strana prefiksnog drveta je to što složenost umetanja i pretrage zavisi od dužine zapisa ključa, a ne od broja elemenata koji se čuvaju u drvetu. Mana je potreba za čuvanjem pokazivača uz svaki čvor u drvetu. Štaviše, prostorna složenost prefiksnog drveta u najgorem slučaju iznosi \(O(MNK)\), gde je sa \(N\) označen broj ključeva koji se čuvaju u prefiksnom drvetu, a sa \(M\) maksimalna dužina ključa. Naime, maksimalni mogući broj čvorova prefiksnog drveta jednak je \(O(MN)\) i odgovara slučaju kada nema nikakvog preklapanja karaktera među ključevima, dok je prostorna složenost svakog čvora jednaka \(O(K)\) zbog potrebe čuvanja mape u svakom čvoru. Primetimo da je očekivana prostorna složenost manja jer će se u slučaju realne konačne azbuke (na primer, engleske abecede) prvo preklapanje javiti najkasnije nakon 26 ključeva.
Smanjenje memorijske složenosti se može postići i tako što se smanji veličina azbuke (po cenu povećanja dužine ključa). Na primer, umesto 256 različitih 8-bitnih karaktera, možemo svaki karakter podeliti na dve 4-bitne polovine. Na ovaj način dobija se samo 16 različitih 4-bitnih karaktera, ali se dužina svakog ključa dva puta povećava.
Kada bi se umesto prefiksnog drveta koristilo balansirano uređeno binarno drvo koje bi čuvalo kompletne ključeve u čvorovima (slika 1), vremenska složenost operacija pretraživanja, umetanja i brisanja bi u najgorem slučaju bila \(O(M\cdot\log N)\), gde je sa \(N\) označen ukupan broj ključeva koji se čuvaju u drvetu, a sa \(M\) maksimalna dužina ključa. Prostorna složenost ove strukture je \(O(M\cdot N)\).
Kada bi se koristila heš tabela, prilikom svake operacije umetanja i pretrage bi morala da bude izračunata heš vrednost ključa koji se traži za šta je potrebno vreme \(O(M)\). U zavisnosti od broja kolizija, vršila bi se poređenja heš vrednosti (u najgorem slučaju njih \(O(N)\), a amortizovano \(O(1)\)). Na kraju bi ključ koji se traži i ključ sloga koji je pronađen na osnovu jednakosti heš-vrednosti morali da budu eksplicitno upoređeni, za šta je takođe potrebno vreme \(O(M)\) (a ako postoje kolizije ovo poređenje bi moralo da se izvrši nekoliko puta). Zato bi složenost najgoreg slučaja operacija bila \(O(N + M)\), a amortizovana složenost \(O(M)\). Pošto ključ mora biti zapisan eksplicitno u svakom slogu tabele, prostorna složenost pristupa zasnovanog na heš tabelama je \(O(M\cdot N)\).
U tabeli 1 prikazana je (amortizovana) složenost raznih implementacija skupova/mapa. Pretpostavljamo da je dužina reči koja se obrađuje \(m\), broj reči u kolekciji \(N\), a veličina azbuke \(K\).
| Heš tabela | Balansirano binarno uređeno drvo | Prefiksno drvo | |
|---|---|---|---|
| Pretraga | \(O(m)\) | \(O(m \log{N})\) | \(O(m)\) |
| Umetanje | \(O(m)\) | \(O(m \log{N})\) | \(O(m)\) |
| Brisanje | \(O(m)\) | \(O(m \log{N})\) | \(O(m)\) |
| Prostor | \(O(mN)\) | \(O(mN)\) | \(O(mNK)\) |
Dakle, možemo primetiti da prefiksno drvo nema lošiju složenost od heš-tabela, ali podržava novu operaciju (pronalaženje svih reči koje imaju dati prefiks) i stoga se koristi prilikom rešavanja problema u kojima je ta operacija korisna.
Zadaci:
Kod asocijativnih struktura podataka pristup elementima se vrši na osnovu vrednosti ključa, a ne na osnovu indeksa, odnosno pozicije elementa u strukturi podataka.↩︎