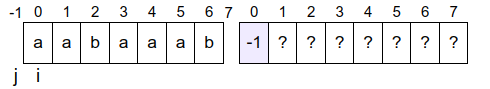Direktni algoritam za traženje niske \(p\) dužine \(|p|=m\) u tekstu \(t\) dužine \(|t|=n\) poredi nisku \(p\) sa svim mogućim segmentima \(t_k t_{k+1}\ldots t_{k+m-1}\) teksta \(t\), za \(k=0,1,\ldots, n-m+1\). Upoređivanje niske \(p\) sa tekućim segmentom vrši se karakter po karakter sleva udesno, sve dok se ne ustanovi da su svi karakteri niske jednaki odgovarajućim karakterima segmenta (u tom trenutku prekida se dalje pregledanje segmenta) ili dok se ne naiđe na neslaganje karaktera, odnosno kada se desi \(p_i\neq t_{k+i-1}\) za neko \(i\), \(0\le i\le m-1\). U drugom slučaju niska koja se traži se “pomera” za jedan karakter udesno, odnosno nastavlja se sa proverom jednakosti karaktera \(p_0\) niske \(p\) sa karakterom \(t_{k+1}\) teksta \(t\). Broj upoređivanja karaktera je u najgorem slučaju reda \(mn\) (mada će se u praksi često mnogo brže naići na neslaganje niske i tekućeg segmenta), pa je složenost ovog algoritma \(O(mn)\) u najgorem slučaju.
U opisanom direktnom algoritmu za traženje niske u tekstu nakon pomeranja niske za jedno mesto udesno ignorišu se sve informacije o prethodno poklopljenim karakterima. Stoga je moguće da se jedan isti karakter teksta više puta obrađuje tj. da se poredi sa različitim karakterima niske.
Primer 7.6.1. Razmotrimo problem traženja niske \(p=aaaab\) u tekstu \(t=aaaaaaaaaa\). Nakon uspešnog poređenja četiri karaktera \(a\) teksta \(t\) i niske \(p\) i nepoklapanja karaktera \(a\) teksta i karaktera \(b\) niske \(p\), nisku \(p\) bismo pomerili udesno za jednu poziciju. Nakon toga bismo ponovo (uspešno) poredili četiri karaktera \(a\) teksta \(t\) i niske \(p\) (iako smo za tri od njih već mogli da zaključimo da će se ti karakteri poklopiti) a zatim nakon nepoklapanja karaktera \(a\) sa karakterom \(b\) opet pomerili nisku \(p\) za jednu poziciju udesno itd.
Algoritam koji su nezavisno osmislili Donald Knut, Džejms Moris i Von Prat a koji je poznat pod nazivom Knut-Moris-Pratov algoritam (ili skraćeno algoritam KMP) zasniva se na ideji da se iskoriste informacije dobijene prethodnim poređenjima karaktera i da se nikada iznova ne porede karakteri teksta \(t\) koji su se prethodno uspešno poklopili sa niskom \(p\). Na ovaj način faza traženja niske u tekstu je složenosti \(O(n)\). Da bi ovo bilo izvodljivo, na početku algoritma vrši se pretprocesiranje niske \(p\) u cilju analize njene strukture. Faza pretprocesiranja je složenosti \(O(m)\), te je ukupna složenost algoritma KMP \(O(m+n)\). Algoritam KMP se često koristi kada se niska traži u dugačkom tekstu čija je azbuka male kardinalnosti, na primer kada se pretražuju molekuli DNK koji se opisuju nizom slova iz četvoroslovne azbuke \(A,C,G,T\).
Pre opisa algoritma KMP uvedimo osnovnu terminologiju koja se u njemu koristi. Neka je \(x=x_0\ldots x_{k-1}\) niska dužine \(k\). Važi sledeće:
niska \(y\) dužine \(l\) (\(0 \leq l \leq k\)) je prefiks niske \(x\) ako je \(y=x_0\ldots x_{l-1}\) ;
niska \(y\) dužine \(l\) (\(0 \leq l \leq k\)) je sufiks niske \(x\) ako je \(y=x_{k-l}\ldots x_{k-1}\);
za prefiks (sufiks) \(y\) kažemo da je pravi prefiks (pravi sufiks) niske \(x\) ako je \(y\neq x\), odnosno ako je njegova dužina strogo manja od dužine niske \(x\);
niska \(y\) dužine \(l\) je prefiks-sufiks niske \(x\) ako je \(0 \leq l < k\), \(y=x_0\ldots x_{l-1}\) i istovremeno \(y=x_{k-l}\ldots x_{k-1}\), odnosno ako je niska \(y\) istovremeno i pravi prefiks i pravi sufiks niske \(x\).
Primer 7.6.2. Neka je \(x=abacab\). Označimo sa \(\epsilon\) praznu nisku. Pravi prefiksi niske \(x\) su \(\epsilon,a,ab,aba,abac,abaca\), a pravi sufiksi \(\epsilon,b,ab,cab,acab,bacab\). Dakle, prefiks-sufiksi niske \(x\) su \(\epsilon\) (dužine \(0\)) i \(ab\) (dužine \(2\)).
Primer 7.6.3. Prefiks-sufiksi niske \(x=aaaaa\) su \(\epsilon,a,aa,aaa,aaaa\).
Prazna niska je uvek prefiks-sufiks niske \(x\), osim ako je niska \(x\) prazna (prazna niska nema prefiks-sufiks).
U narednom primeru ilustrovaćemo kako pojam prefiks-sufiksa može pomoći prilikom izračunavanja vrednosti za koju treba pomeriti nisku \(p\) u odnosu na tekst \(t\), kada dođe do nepoklapanja karaktera niske \(p\) i teksta \(t\).
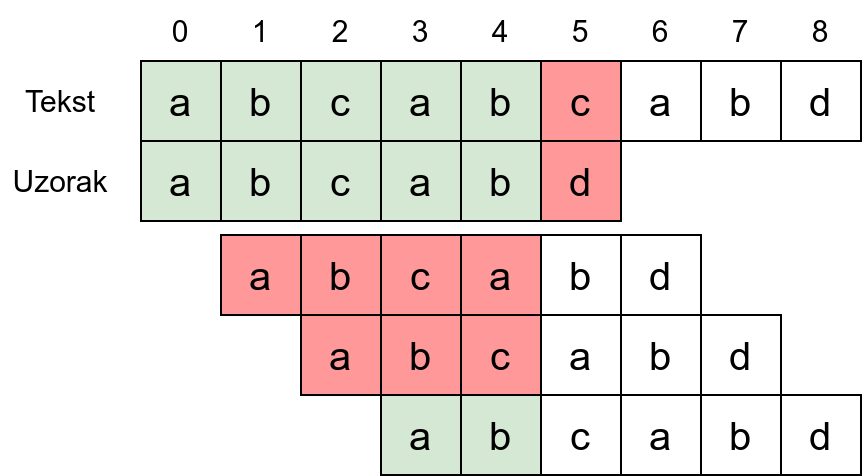
Primer 7.6.4. Na slici 1 prikazan je početak traženja niske \(abcabd\) unutar teksta \(abcabcabd\).
Slika 1: Primer pretrage niske.
Karakteri \(abcab\) na pozicijama od \(0\) do \(4\) u niski \(p\) i tekstu \(t\) su se poklopili, dok se karakteri na poziciji \(5\) razlikuju (u tekstu \(t\) se nalazi karakter \(c\), a u niski \(p\) karakter \(d\)). Interesuje nas za koliko najmanje treba pomeriti nisku \(p\) udesno u odnosu na tekst \(t\), tako da se ponovo neki (kraći) prefiks niske \(p\) poklopi sa tekstom \(t\).
Da bi se poklapanje dogodilo nakon pomeranja za jedno mesto udesno, potrebno je da se deo teksta \(bcab\) poklopi sa delom niske \(abca\), što nije slučaj. Primetimo da je \(bcab\) sufiks, a \(abca\) prefiks dela niske (prefiksa niske) \(abcab\) za koji smo utvrdili da se poklapa sa tekstom.
Da bi se poklapanje dogodilo nakon pomeranja za dva mesta udesno, potrebno je da se deo teksta \(cab\) poklopi sa delom niske \(abc\), što nije slučaj. Opet možemo primetiti da je \(cab\) sufiks, a \(abc\) prefiks dela niske (prefiksa niske) \(abcab\) za koji smo utvrdili da se poklapa sa tekstom.
Da bi se poklapanje dogodilo nakon pomenranja za tri mesta udesno, potrebno je da se deo teksta \(ab\) poklopi sa delom niske \(ab\), što ovaj put jeste slučaj. Niska \(ab\) je i sufiks i prefiks dela niske (prefiksa niske) \(abcab\) i zapravo je najduži prefiks-sufiks tog poklopljenog dela niske.
Dakle, nekoliko poslednjih karaktera poklopljenog prefiksa niske \(p\) treba da se poklope sa nekoliko prvih karaktera tog prefiksa niske \(p\), te je nama, u stvari, potreban neki prefiks-sufiks poklopljenog prefiksa niske \(p\). S obzirom na to da želimo da se pomerimo udesno što je manje moguće, mi u stvari tražimo najduži prefiks-sufiks poklopljenog prefiksa niske \(p\).
U ovom primeru, poklopljeni prefiks niske \(p\) je \(abcab\) i njegova dužina je \(5\). Njegov najduži prefiks-sufiks je \(ab\) i dužine je \(2\). Dakle, nisku pomeramo udesno u odnosu na tekst za \(5-2=3\) karaktera.
Ako je niska \(abcabd\) i tekst počinje sa \(abcdxy\), poklopljeni prefiksa niske je \(abc\) i dužina mu je \(3\). Njegov najduži prefiks-sufiks je prazna niska \(\varepsilon\) i dužina mu je \(0\), te nisku pomeramo udesno za \(3-0=3\) karaktera.
Pošto dužina poklopljenog dela niske \(p\) i teksta \(t\) zavisi i od samog teksta \(t\), odnosno ne znamo unapred za koje prefikse niske \(p\) će nam biti potrebni najduži prefiksi-sufiksi, u fazi pretprocesiranja potrebno je odrediti dužinu najdužeg prefiks-sufiksa svakog prefiksa date niske \(p\). Nakon toga, u fazi pretrage, na osnovu prefiksa niske \(p\) koji se poklopio sa tekstom \(t\), tj. dužine njegovog najdužeg prefiks-sufiksa, jednostavno se utvrđuje za koliko mesta treba pomeriti nisku \(p\) u odnosu na tekst \(t\).
Primetimo veliku sličnost niza dužina prefiks-sufiksa i z-niza (opisanog u pogavlju 7.5). Na svakoj poziciji u z-nizu se nalazi dužina najduže podniske koja počinje na toj poziciji i jednaka je nekom prefiksu niske, dok se kod algoritma KMP za svaku poziciju određuje najduži pravi prefiks-sufiks, što je dužina najduže podniske koja se završava na toj poziciji i jednaka je nekom prefiksu niske.
7.6.1 Pretprocesiranje niske koja se traži
Posvetimo se sada pitanju kako se za datu nisku \(p = p_0\ldots p_{m-1}\) dužine \(m\) mogu efikasno odrediti dužine najdužih prefiks-sufiksa svih njenih prefiksa. U fazi pretprocesiranja niske \(p\) izračunaćemo vrednosti niza \(\pi\) dužine \(m+1\) koji će čuvati vrednosti prefiksne funkcije (engl. prefix function) niske \(p\), tako da je \(\pi_i\) dužina najdužeg prefiks-sufiksa prefiksa \(p_0\ldots p_{i-1}\) dužine \(i\) date niske \(p\). Primenićemo induktivni pristup, tj. dužine najdužih prefiks-sufiksa ćemo izračunavati inkrementalno.
Bazu indukcije čini slučaj \(i=0\), tj. slučaj praznog prefiksa \(\epsilon\) (prefiksa dužine 0) niske \(p\). On nema prefiks-sufikse, a vrednost \(\pi_0\) ćemo postaviti na \(-1\).
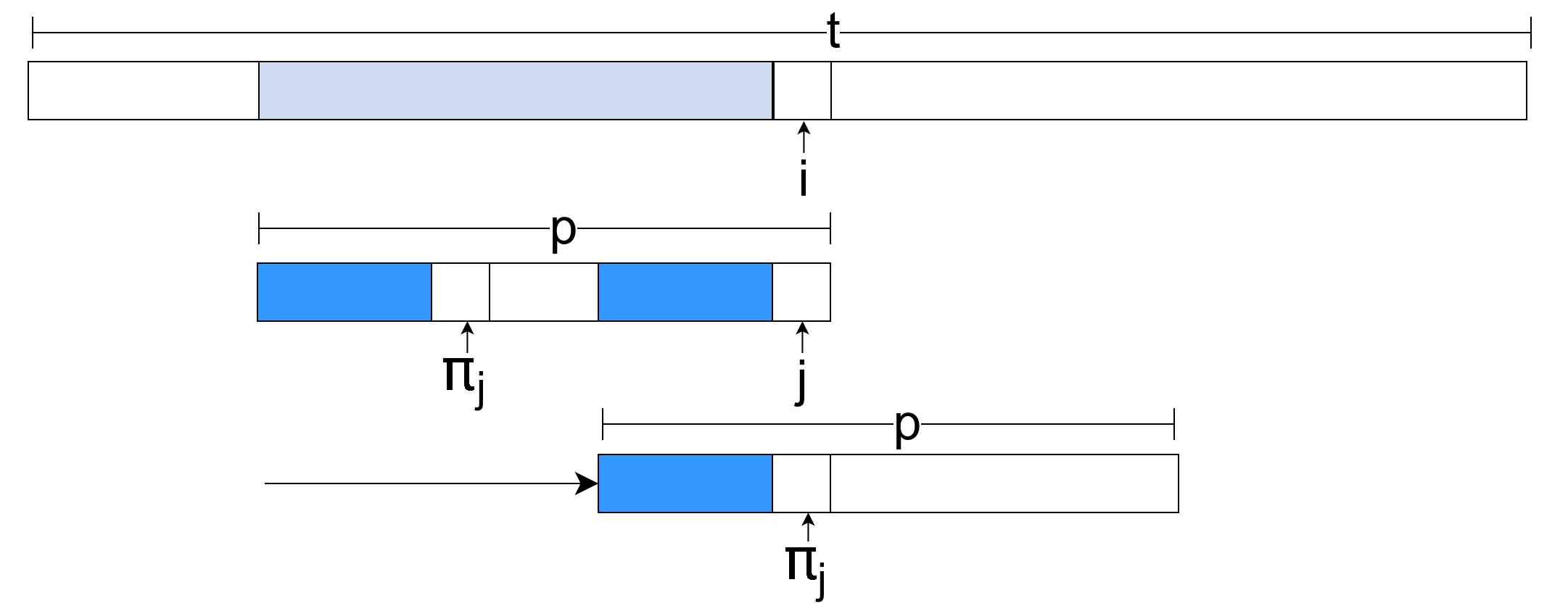
Pretpostavimo da smo odredili vrednosti \(\pi_0, \ldots, \pi_i\) i razmotrimo kako se na osnovu tih vrednosti može odrediti vrednost \(\pi_{i+1}\). Neka je \(x=p_0\ldots p_{i-1}\). Vrednost \(\pi_{i+1}\) jednaka je dužini najdužeg prefiks-sufiksa niske \(p_0\ldots p_{i-1}p_i = xp_i\). Svaki prefiks-sufiks niske \(xp_i\) dobija se tako što se neki prefiks-sufiks \(r\) (dužine \(j<i\)) niske \(x\) proširi karakterom \(a=p_i\) (slika 2).
Slika 2: Proširivanje prefiks-sufiksa.
Da bi prefiks-sufiks niske \(xp_i\) bio što duži, potrebno je da i prefiks-sufiks \(r\) bude što duži. Dakle, do najdužeg prefiks-sufiksa niske \(xp_i\) možemo doći tako što analiziramo redom prefiks-sufikse niske \(x\) od najdužeg, ka najkraćem (a to je \(\varepsilon\)). Ako za neki prefiks-sufiks \(r=p_0\ldots p_{j-1}\) dužine \(j\) važi \(p_j = p_i\), tada je najduži prefiks-sufiks niske \(xp_i\) niska \(rp_i\), pa je \(\pi_{i+1} = j+1\). Ako ni za jedan prefiks-sufiks \(r\) niske \(x\) to ne važi, tada je jedini prefiks-sufiks niske \(xp_i\) prazna niska \(\epsilon\), pa je \(\pi_{i+1} = 0\).
Ostaje još pitanje kako nabrojati sve prefiks-sufikse niske \(x=p_0\ldots p_{i-1}\). Dužina najdužeg od njih je poznata i jednaka je \(\pi_i\), pa je najduži prefiks-sufiks niske \(x\) niska \(p_0\ldots p_{\pi_i-1}\). Naredna lema nam daje način da poznajući jedan prefiks-sufiks niske \(x\) odredimo i sve ostale.
Lema 7.6.1. Neka su \(r\) i \(s\) prefiks-sufiksi niske \(x\), pri čemu važi \(|r|<|s|\). Tada je niska \(r\) prefiks-sufiks niske \(s\).
Dokaz. Niska \(r\) je prefiks niske \(x\), pa je i pravi prefiks niske \(s\), jer je kraća od nje. Niska \(r\) je istovremeno sufiks niske \(x\), te je stoga i pravi sufiks niske \(s\). Stoga je \(r\) prefiks-sufiks niske \(s\) (slika ??).
\(\Box\)
Dakle, ako je niska \(r_1\) najduži prefiks-sufiks niske \(x\), sledeći po redu najduži prefiks-sufiks \(r_2\) niske \(x\) se dobija kao najduži prefiks-sufiks niske \(r_1\). Naredni po redu najduži prefiks-sufiks \(r_3\) niske \(x\) je najduži prefiks-sufiks niske \(r_2\) i tako dalje.
Pošto je \(\pi_i\) dužina najdužeg prefiks-sufiksa niske \(x\), karakteri \(p_0,p_1,\ldots,p_{\pi_i-1}\) i \(p_{i-\pi_i},\ldots,p_{i-1}\) niske se poklapaju i potrebno je proveriti da li važi \(p_{\pi_i}=p_i\) (slika 3).
Slika 3: Prefiks dužine \(i\) niske sa prefiks-sufiksom dužine \(\pi_i\).
Ako se ne poklapaju, razmatra se prvi naredni kraći prefiks-sufiks niske \(x\). On će biti jednak najdužem prefiks-sufiksu najdužeg prefiks-sufiksa prefiksa niske dužine \(i\). Dakle, on će biti jednak prefiksu niske \(x\) dužine \(\pi_{\pi_i}\), te je potrebno uporediti karaktere \(p_{\pi_{\pi_i}}\) i \(p_i\). Ako se ti karakteri ne poklope, postupak se nastavlja na isti način.
Dakle, prilikom računanja vrednosti \(\pi_{i+1}\), promenljiva \(j\) će u petlji uzimati redom vrednosti \(\pi_i, \pi_{\pi_i}, \pi_{\pi_{\pi_i}}\ldots\) Prefiks-sufiks dužine \(j\) može se proširiti karakterom \(p_i\) ako je \(p_j=p_i\). Ako to nije slučaj, naredni najduži prefiks-sufiks niske \(x\) se određuje postavljanjem \(j=\pi_j\). Petlja se prekida ako se nijedan prefiks-sufiks ne može proširiti. Zahvaljući tome što smo postavili \(\pi_0=-1\), kada se to desi, petlja se prekida kada je \(j=-1\), jer uslov \(j \geq 0\) nije ispunjen. Na kraju izvršavanja petlje vrednost promenljive \(j\) uvećana za 1 sadržaće dužinu najdužeg prefiks-sufiksa niske \(x=p_0\ldots p_i\) i nju treba smestiti na poziciju \(\pi_{i+1}\) (ovo važi i u slučaju kada je došlo do poklapanja \(p_j = p_i\), ali, opet zahvaljujući odluci da je \(\pi_0=-1\), i kada je petlja prekinuta jer je \(j=-1\), što znači da je prazna reč najduži prefiks-sufiks).
vector<int> kmpIzracunajPrefiksSufikse(const string &p) {int m = p.size() + 1; vector<int> pi(m);int i = 0;int j = -1;// prazna niska nema prefiks-sufikse pi[i] = j;// za prefiks duzine i polazne niske racunamo najduzi prefiks-sufikswhile (i + 1 < m) {// proveravamo da li se najduzi prefiks-sufiks prefiksa uzorka duzine i// moze prosiriti: to vazi ako je p[i] = p[j]while (j >= 0 && p[i] != p[j]) j = pi[j]; pi[++i] = ++j; }return pi;}
#include <iostream>#include <string>#include <vector>usingnamespace std;vector<int> kmpIzracunajPrefiksSufikse(const string &p) {int m = p.size() + 1; vector<int> pi(m);int i = 0;int j = -1;// prazna niska nema prefiks-sufikse pi[i] = j;// za prefiks duzine i polazne niske racunamo najduzi prefiks-sufikswhile (i + 1 < m) {// proveravamo da li se najduzi prefiks-sufiks prefiksa uzorka duzine i// moze prosiriti: to vazi ako je p[i] = p[j]while (j >= 0 && p[i] != p[j]) j = pi[j]; pi[++i] = ++j; }return pi;}vector<int> traziKMP(const string& p, const string& t) { vector<int> pozicije; vector<int> pi = kmpIzracunajPrefiksSufikse(p);int n = t.size();int m = p.size();int i = 0;int j = 0;// proveravamo tekuci karakter teksta sve dok postoji mogućnost da se // do kraja teksta pronadje niskawhile (i + m - j <= n) {// proveravamo da li se najduzi prefiks-sufiks// prefiksa niske p koji se zavrsava na prethodnoj poziciji// moze prosiriti: to vazi ako je t[i] = p[j]while (j >= 0 && t[i] != p[j]) j = pi[j]; i++; j++;// ako smo poklopili svih m karaktera niske pamtimo poziciju poklapanjaif (j == m) pozicije.push_back(i - m); }return pozicije;}int main() { string p, t; cin >> p >> t; vector<int> pozicije = traziKMP(p, t);if (pozicije.empty()) cout << -1 << endl;else {for (int poz : pozicije) cout << poz << " "; cout << endl; }return0;}
Primer 7.6.5. Prikažimo pretprocesiranje, tj. izračunavanje najdužih prefiks-sufiksa niske \(aabaaab\). Nakon inicijalizacije promenljivih, važi \(j=-1\), \(i=0\), \(\pi_0 = -1\).
Sada određujemo vrednost \(\pi_1\) tj. dužinu najdužeg prefiks-sufiksa niske \(a\) (tj. prefiksa niske \(p\) dužine \(1\), koji se završava na poziciji \(i=0\)). Njen jedini prefiks-sufiks je prazna niska, pa je \(\pi_1=0\) (u unutrašnju petlju se ne ulazi jer je \(j = -1 < 0\)). Ovo je ilustrovano na narednoj slici.
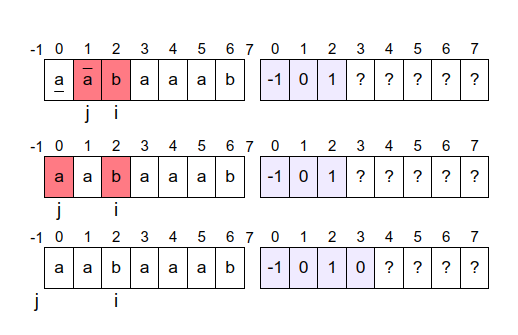
Nakon toga se uvećavaju vrednosti promenljivih \(i\) i \(j\) i postaju \(i=1\) i \(j=0\) (tada se vrši dodela pi[1] = 0) i prelazi se na određivanje vrednosti \(\pi_2\) tj. dužine najdužeg prefiks-sufiksa niske \(aa\) (tj. prefiksa niske \(p\) dužine \(2\), koji se završava na poziciji \(i=1\)). Najduži prefiks-sufiks niske \(a\) je prazna niska, a pošto je \(p_j = p_0 = a = p_1 = p_i\), on se može produžiti karakterom \(a\), pa je \(a\) najduži prefiks-sufiks niske \(aa\) i \(\pi_2=1\). Ovo je ilustrovano na narednoj slici.
Nakon toga se uvećavaju vrednosti promenljivih \(i\) i \(j\) i postaju \(i=2\) i \(j=1\) (tada se vrši dodela pi[2]=1) i prelazi se na određivanje vrednosti \(\pi_3\) tj. dužine najdužeg prefiks-sufiksa niske \(aab\) (tj. prefiksa niske \(p\) dužine \(3\), koji se završava na poziciji \(i=2\)). Najduži prefiks-sufiks niske \(aa\) je \(a\), ali pošto je \(p_j = p_1 = a \neq b = p_2 = p_i\), on se ne može produžiti. Zato analiziramo kraći prefiks-sufiks niske \(aa\), a to je prazna reč (postavljajući vrednost \(j\) na \(\pi_j=\pi_1=0\)). Pošto je \(p_j = p_0 = a \neq p_2 = p_i\), ni on se ne može produžiti. Postavljajući \(j\) na vrednost \(\pi_j = \pi_0 = -1\), prekidamo unutrašnju petlju i zaključujemo da je najduži prefiks-sufiks niske \(aab\) prazna niska i \(\pi_3=0\). Ovo je ilustrovano na narednoj slici.
Nakon toga se uvećavaju vrednosti promenljivih \(i\) i \(j\) i postaju \(i=3\) i \(j=0\) (tada se vrši dodela pi[3]=0) i prelazi se na određivanje vrednosti \(\pi_4\) tj. dužine najdužeg prefiks-sufiksa niske \(aaba\) (tj. prefiksa niske \(p\) dužine \(4\), koji se završava na poziciji \(i=3\)). Najduži prefiks-sufiks niske \(aab\) je prazna niska, a pošto je \(p_j = p_0 = a = p_3 = p_i\), on se može produžiti karakterom \(a\), pa je \(a\) najduži prefiks-sufiks niske \(aaba\) i \(\pi_4=1\). Ovo je ilustrovano na narednoj slici.
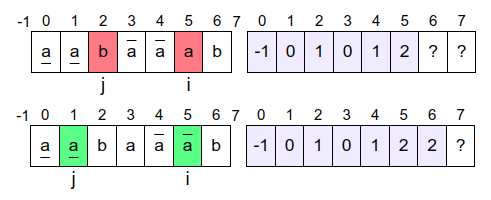
Nakon toga se uvećavaju vrednosti promenljivih \(i\) i \(j\) i postaju \(i=4\) i \(j=1\) (tada se vrši dodela pi[4]=1) i prelazi se na određivanje vrednosti \(\pi_5\) tj. dužine najdužeg prefiks-sufiksa niske \(aabaa\) (tj. prefiksa niske \(p\) dužine \(5\), koji se završava na poziciji \(i=4\)). Najduži prefiks-sufiks niske \(aaba\) je niska \(a\), a pošto je \(p_j = p_1 = a = p_4 = p_i\), on se može produžiti karakterom \(a\), pa je \(aa\) najduži prefiks-sufiks niske \(aabaa\) i \(\pi_5=2\). Ovo je ilustrovano na narednoj slici.
Nakon toga se uvećavaju vrednosti promenljivih \(i\) i \(j\) i postaju \(i=5\) i \(j=2\) (tada se vrši dodela pi[5]=2) i prelazi se na određivanje vrednosti \(\pi_6\) tj. dužine najdužeg prefiks-sufiksa niske \(aabaaa\) (tj. prefiksa niske \(p\) dužine \(6\), koji se završava na poziciji \(i=5\)). Najduži prefiks-sufiks niske \(aabaa\) je niska \(aa\), ali pošto je \(p_j = p_2 = b \neq a = p_5 = p_i\), on se ne može produžiti. Zato analiziramo kraći prefiks-sufiks niske \(aabaa\), a to je \(a\) (postavljajući vrednost \(j\) na \(\pi_j=\pi_2=1\)). Pošto je sada \(p_j = p_1 = a = p_5 = p_i\), ovaj prefiks-sufiks se može produžiti karakterom \(a\), pa je \(aa\) najduži prefiks-sufiks niske \(aabaaa\) i \(\pi_6=2\). Ovo je ilustrovano na narednoj slici.
Nakon toga se uvećavaju vrednosti promenljivih \(i\) i \(j\) i postaju \(i=6\) i \(j=2\) (tada se vrši dodela pi[6]=2) i prelazi se na određivanje vrednosti \(\pi_7\) tj. dužine najdužeg prefiks-sufiksa niske \(aabaaab\) (tj. prefiksa niske \(p\) dužine \(7\), koji se završava na poziciji \(i=6\)). Najduži prefiks-sufiks niske \(aabaaa\) je niska \(aa\), a pošto je \(p_j = p_2 = b = p_6 = p_i\), on se može produžiti karakterom \(b\), pa je \(aab\) najduži prefiks-sufiks niske \(aabaaab\) i \(\pi_7=3\). Ovo je ilustrovano na narednoj slici.
Ovim su određeni najduži prefiks-sufiksi svih prefiksa niske \(p\), pa se algoritam završava (jer nakon uvećavanja vrednosti promenljivih na \(j=3\) i \(i=7\), vrednost \(i\) dostiže dužinu niske \(m=7\)).
Naredni aplet ilustruje fazu pretprocesiranja kod algoritma KMP.
Dužine sve prefiks-sufikse neke niske možemo pronaći i korišćenjem z-niza. Naime, ako za neku poziciju \(k\) važi \(k+z_k = n\), gde je \(n\) dužina niske, tada se podniska koja počinje na poziciji \(k\) i jednaka je nekom prefiksu niske prostire do samog kraja niske i ona je ujedno i sufiks niske. I drugi smer važi: za svaki prefiks-sufiks dužine \(d\) važi \(z_{n-d} = d\) tj. \(n-d + z_{n-d} = n\). Na primer, u narednoj tabeli je prikazan z-niz za nisku \(abacabacaba\).
\(k\)
0
1
2
3
4
5
6
7
8
9
10
\(s_k\)
a
b
a
c
a
b
a
c
a
b
a
\(z_k\)
-
0
1
0
7
0
1
0
3
0
1
\(\pi_{k+1}\)
0
0
1
0
1
2
3
4
5
6
7
Važi \(4 + z_4 = 8 + z_8 = 10 + z_{10} = 11\), pa su pravi sufiks-prefiksi niske \(abacaba\), \(aba\) i \(a\).
Na osnovu poznatog z-niza moguće je odrediti i ceo KMP niz \(\pi\). Ako je \(z_k > 0\), tada je \(s[0..z_k)=s[k..k+z_k)\). Zato i za svako \(j < z_k\) važi da je \(s[0..j]=s[k..k+j]\), pa postoji pravi prefiks-sufiks dužine \(j+1\) niske koja se završava na poziciji \(k+j\). Na primer, pošto je u tekućem primeru \(z_4=7\), sigurno postoji prefiks-sufiks dužine 1 niske koja se završava na poziciji 4 (ovo se dobija za \(k=4\), a \(j=0\) i tada je \(a\) prefiks-sufiks niske \(abaca\)). Slično, sigurno postoji prefiks-sufiks dužine \(7\) niske koja se završava na poziciji \(10\) (ovo se dobija za \(k=4\), \(j=6\) i tada je \(abacaba\) prefiks-sufiks cele niske). Ovako određen prefiks-sufiks ne mora biti i najduži. Na primer, pošto je \(z_8=3\), postoji i prefiks-sufiks dužine \(3\) niske koja se završava na poziciji \(10\) (ovo se dobija za \(k=8\), \(j=2\) i tada je \(aba\) prefiks-sufiks cele niske). Ipak, ako se vrednosti \(k\) obrađuju redom, prvi pronađen prefiks-sufiks za svaku poziciju biće i najduži, pa se obrada prefiks-sufiksa za tu poziciju dobijenih na osnovu narednih pozicija \(k\) može preskočiti. Ovo dovodi do algoritma linearne složenosti (za svako naredno \(k\) dovoljno je obrađivati samo one vrednosti \(j < z_k\), za koje je \(k+j\) desno od poslednje do tada određene vrednosti niza \(\pi\)).
Moguće je i na osnovu poznatih vrednosti niza \(\pi\) dobiti vrednosti niza \(z\).
7.6.2 Pretraživanje teksta
Osnovna varijanta pretrage teksta se može dobiti prilagođavanjem algoritma grube sile. Spoljašnja petlja obilazi pozicije \(i\) u tekstu sa kojih se počinje pretraga niske. U unutrašnjoj petlji se prolazi kroz karaktere niske (od početka) i karaktere teksta (od pozicije \(i\)) sve dok se ne dođe do kraja niske ili do različitog karaktera. Ako se dođe do kraja niske, pronađeno je poklapanje. Ako nije, algoritam grube sile uvećava poziciju \(i\) za 1, dok se kod algoritma KMP pozicija \(i\) uvećava za \(j - \pi_j\), gde je \(j\) pozicija u niski na kojoj se naišlo na nepoklapajući karakter (tj. dužina uspešno poklopljenog prefiksa niske), a \(\pi_j\) dužina najdužeg prefiks-sufiksa tog dela niske. Pošto je već ustanovljeno da se prvih \(\pi_j\) karaktera niske \(p\) nakon pomeranja poklapaju sa tekstom, poređenje se nastavlja od karaktera \(\pi_j\) te niske tj. promenljiva \(j\) se postavlja na \(\pi_j\) (pri čemu treba obratiti pažnju na specijalni slučaj \(j=0\) tj. \(\pi_0=-1\) treba posebno obraditi).
vector<int> traziKMP(const string &p, const string &t) {// duzine prefiks-sufiksa svih prefiksa niske p vector<int> b = kmpIzracunajPrefiksSufikse(p);// pozicije poklapanja u tekstu vector<int> pozicije;// proveravamo pojavljivanje nniske krenuvsi od pozicije i u tekstuint i = 0, j = 0;while (i + p.size() <= t.size()) {// analiziramo jedan po jedan karakter niskewhile (j < p.size()) {if (t[i + j] != p[j])break; j++; }// ako smo stigli do kraja niske, ona je pronadjena na poziciji i u tekstuif (j == p.size()) pozicije.push_back(i);// pomeramo se udesno na osnovu algoritma KMP i znamo da se prvih b[j]// karaktera vec poklapaju i += j - b[j]; j = max(b[j], 0); }return pozicije;}
#include <iostream>#include <string>#include <vector>usingnamespace std;vector<int> kmpIzracunajPrefiksSufikse(const string &p) {int m = p.size() + 1; vector<int> b(m);int i = 0;int j = -1;// prazna niska nema prefiks-sufikse b[i] = j;// za prefiks duzine i polazne niske racunamo najduzi prefiks-sufikswhile (i + 1 < m) {// proveravamo da li se najduzi prefiks-sufiks prefiksa uzorka duzine i// moze prosiriti: to vazi ako je p[i] = p[j]while (j >= 0 && p[i] != p[j]) j = b[j]; b[++i] = ++j; }return b;}vector<int> traziKMP(const string &p, const string &t) {// duzine prefiks-sufiksa svih prefiksa niske p vector<int> b = kmpIzracunajPrefiksSufikse(p);// pozicije poklapanja u tekstu vector<int> pozicije;// proveravamo pojavljivanje nniske krenuvsi od pozicije i u tekstuint i = 0, j = 0;while (i + p.size() <= t.size()) {// analiziramo jedan po jedan karakter niskewhile (j < p.size()) {if (t[i + j] != p[j])break; j++; }// ako smo stigli do kraja niske, ona je pronadjena na poziciji i u tekstuif (j == p.size()) pozicije.push_back(i);// pomeramo se udesno na osnovu algoritma KMP i znamo da se prvih b[j]// karaktera vec poklapaju i += j - b[j]; j = max(b[j], 0); }return pozicije;}int main() { string uzorak, tekst; cin >> uzorak >> tekst; vector<int> pozicije = traziKMP(uzorak, tekst);if (pozicije.empty()) cout << -1 << endl;else {for (int p : pozicije) cout << p << " "; cout << endl; }return0;}
Moguće su i drugačije implementacije.
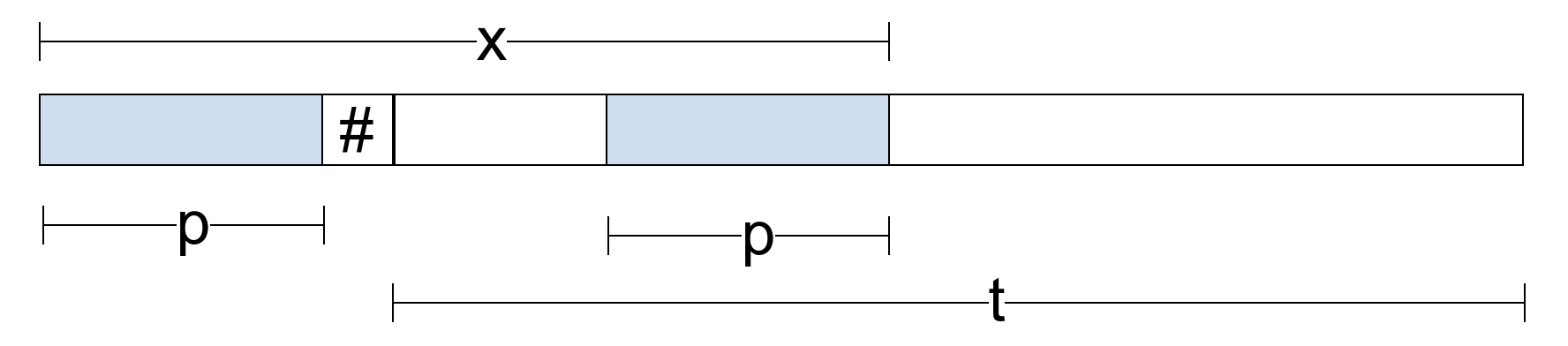
Slično kao kod \(z\)-algoritma, pronalazak svih pojavljivanja niske \(p\) u tekstu \(t\) se može svesti na pretprocesiranje niske \(p\#t\), gde je sa \(\#\) označen specijalni karakter koji se ne javlja ni u tekstu \(t\) ni u niski \(p\). Tada svakom pojavljivanju niske \(p\) u tekstu \(t\) odgovara po jedan prefiks-sufiks dužine \(m\) (slika 4).
Slika 4: Prefiks-sufiks dužine \(m=|p|\) prefiksa \(x\) niske \(p\#t\) odgovara pojavljivanju prefiksa \(p\) u tekstu \(t\).
Alternativno, drugu fazu, tj. algoritam kojim se traži niska \(p\) u tekstu \(t\) na osnovu poznatih dužina prefiks-sufiksa dobijenih u fazi pretprocesiranja niske, možemo implementirati u vidu zasebne funkcije. Taj algoritam je vrlo sličan algoritmu pretprocesiranja niske, jedino što se porede karakteri \(t_i\) (karakter na poziciji \(i\) u tekstu \(t\)) i \(p_j\) (karakter na poziciji \(j\) u niski \(p\)).
Kada se u unutrašnjoj while petlji naiđe na nepoklapanje, razmatra se najduži prefiks-sufiks poklapajućeg prefiksa dužine \(j\) niske (slika 5) i niska se pomera tako što se vrednost \(j\) zameni njenom dužinom \(\pi_j\). To se radi sve dok se karakteri \(p_j\) i \(t_i\) ne poklope ili dok se zaključi da kraći prefiks-sufiks prefiksa niske ne postoji (\(j=-1\)). Nakon toga imamo novi poklapajući prefiks niske i nastavljamo sa spoljašnjom while petljom. Ukoliko smo naišli na poklapanje svih \(m\) karaktera niske (kada važi \(j=m\)), evidentiramo da smo pronašli nisku u tekstu počev od pozicije \(i-j\). Nakon toga, niska se pomera udesno u odnosu na tekst na osnovu svog najdužeg prefiks-sufiksa.
Slika 5: Kada se naiđe na nepoklapanje karaktera \(p_j\) (karaktera na poziciji \(j\) u niski) i karaktera \(t_i\) (karaktera na poziciji \(i\) u tekstu), prelazi se na poređenje karaktera \(p_{\pi_j}\) (karaktera na poziciji \(\pi_j\) u niski) i karaktera \(t_i\), što odgovara pomeranju niske udesno za \(j-\pi_j\).
Implementacija pretrage u jeziku C++ može biti sledeća:
vector<int> traziKMP(const string& p, const string& t) { vector<int> pozicije; vector<int> pi = kmpIzracunajPrefiksSufikse(p);int n = t.size();int m = p.size();int i = 0;int j = 0;// proveravamo tekuci karakter teksta sve dok postoji mogućnost da se // do kraja teksta pronadje niskawhile (i + m - j <= n) {// proveravamo da li se najduzi prefiks-sufiks// prefiksa niske p koji se zavrsava na prethodnoj poziciji// moze prosiriti: to vazi ako je t[i] = p[j]while (j >= 0 && t[i] != p[j]) j = pi[j]; i++; j++;// ako smo poklopili svih m karaktera niske pamtimo poziciju poklapanjaif (j == m) pozicije.push_back(i - m); }return pozicije;}
#include <iostream>#include <string>#include <vector>usingnamespace std;vector<int> kmpIzracunajPrefiksSufikse(const string &p) {int m = p.size() + 1; vector<int> pi(m);int i = 0;int j = -1;// prazna niska nema prefiks-sufikse pi[i] = j;// za prefiks duzine i polazne niske racunamo najduzi prefiks-sufikswhile (i + 1 < m) {// proveravamo da li se najduzi prefiks-sufiks prefiksa uzorka duzine i// moze prosiriti: to vazi ako je p[i] = p[j]while (j >= 0 && p[i] != p[j]) j = pi[j]; pi[++i] = ++j; }return pi;}vector<int> traziKMP(const string& p, const string& t) { vector<int> pozicije; vector<int> pi = kmpIzracunajPrefiksSufikse(p);int n = t.size();int m = p.size();int i = 0;int j = 0;// proveravamo tekuci karakter teksta sve dok postoji mogućnost da se // do kraja teksta pronadje niskawhile (i + m - j <= n) {// proveravamo da li se najduzi prefiks-sufiks// prefiksa niske p koji se zavrsava na prethodnoj poziciji// moze prosiriti: to vazi ako je t[i] = p[j]while (j >= 0 && t[i] != p[j]) j = pi[j]; i++; j++;// ako smo poklopili svih m karaktera niske pamtimo poziciju poklapanjaif (j == m) pozicije.push_back(i - m); }return pozicije;}int main() { string p, t; cin >> p >> t; vector<int> pozicije = traziKMP(p, t);if (pozicije.empty()) cout << -1 << endl;else {for (int poz : pozicije) cout << poz << " "; cout << endl; }return0;}
Primer 7.6.6. Vratimo se na primer 7.6.1 i razmatrimo kako bi pretraga izgledala primenom algoritma KMP.
Dužine prefiks-sufiksa niske \(p=aaaab\) su određene sledećom tabelom.
0
1
2
3
4
5
\(\pi\)
-1
0
1
2
3
0
Pretraga teksta \(t=aaaaaaaaaa\) počinje od pozicije \(0\) i nailazi se na nepoklapanje na poziciji \(4\) u niski \(p\). Zato se traži najduži prefiks-sufiks prva 4 karaktera niske \(p\) (tj. njenog prefiksa \(aaaa\)). Njegova dužina je \(3\), pa se u tekstu pomeramo nadesno za \(4-3\) tj. za jedan karakter. Pošto znamo da se prefiks uzorka dužine \(3\) već poklapa sa tekstom, poređenje može da se nastavi na poziciji \(j=\pi_j=3\) uzorka (koji se poredi sa karakterom na pozicji \(i+j=1+3=4\) u tekstu).
Pošto je \(p_3=t_4=a\), uvećavaju se \(i\) i \(j\) i nailazi se na sledeće nepokapanje \(p_4=b\neq a=t_5\). Do nepoklapanja je došlo ponovo na poziciji 4 u niski \(p\), pa se tekst ponovo pomera za jednu poziciju i postupak se na praktično isti način nastavlja do kraja teksta.
Primetimo da smo u svakom (osim prvom) koraku spoljašnje petlje vršili samo dva poređenja karaktera (jedno uspešno i jedno neuspešno). Isto bi se dešavalo i da je niska \(p\) mnogo duža, što je značajno unapređenje u odnosu na naivni algoritam koji bi u svakom koraku unutrašnje petlje poredio sve karaktere niske \(p\).
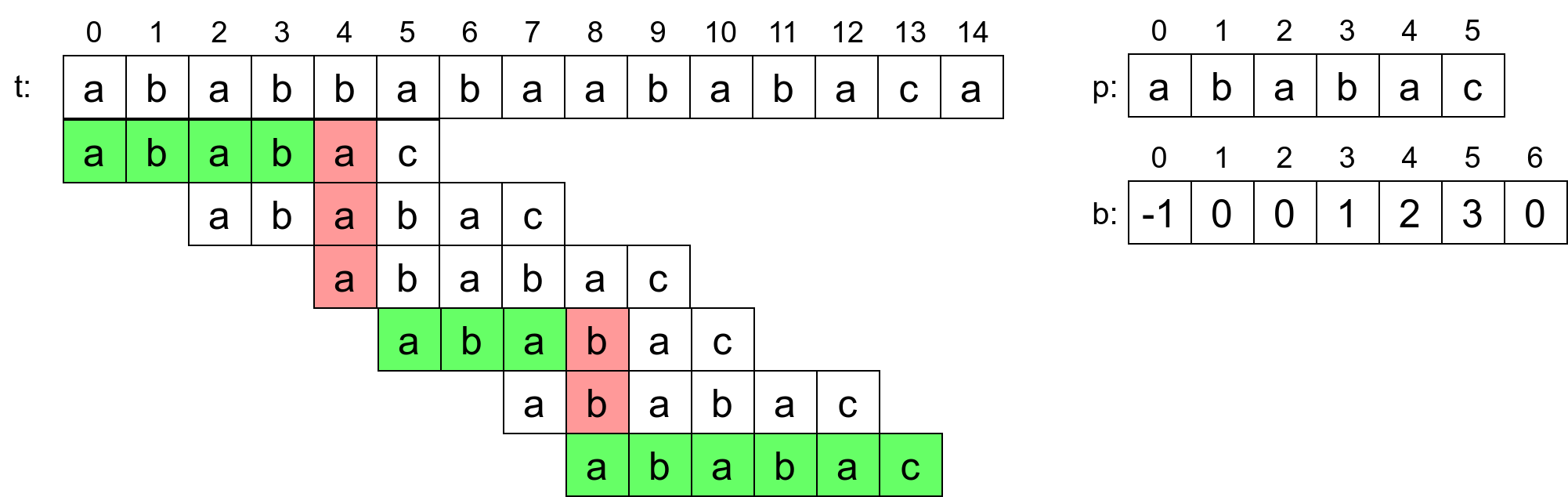
Primer 7.6.7. Razmotrimo koja se poređenja izvršavaju u algoritmu KMP, prilikom traženja niske \(ababac\) u tekstu \(ababbabaababaca\). Uspešna poređenja karaktera su priikazana zelenom, a poređenja kod kojih se nije naišlo na poklapanje, crvenom bojom (slika 6).
Slika 6: Druga faza KMP-algoritma.
Na početku se uspešno poklapaju karakteri \(abab\) nakon čega se nailazi na razliku između karaktera \(t_4=b\) i \(p_4 = a\). Pošto je \(ab\) najduži prefiks-sufiks poklopljenog dela \(abab\) i njegova dužina je \(2\) (tj. pošto je \(\pi_4=2\)), vrednost promenljive \(j\) se postavlja na \(2\) i porede se karakteri \(t_4=b\) i \(p_2=a\). Ponovo nema poklapanja. Pošto je sada poklopljena niska \(ab\), a njen najduži prefiks-sufiks je prazna reč (tj. pošto je \(\pi_2=0\)), prelazi se na poređenje karaktera \(t_4=b\) i \(t_0=a\). I oni su različiti, važi \(\pi_0 = -1\), što znači da se \(i\) uvećava, \(j\) postavlja na nulu i prelazi se na karakter \(t_5=a\). Uspešno se poklapa prefiks \(aba\), nakon čega se nailazi na razliku \(t_8=a\), a \(p_3=b\). Pošto je \(a\) najduži prefiks-sufiks poklopljenog dela \(aba\) (tj. pošto je \(\pi_3=1\)), promenljiva \(j\) se postavlja na \(1\) i porede se karakteri \(t_8=a\) i \(p_1=b\). Pošto su i oni različiti, a pošto je prazna reč najduži prefiks-sufiks poklopljenog dela \(a\) (tj. pošto je \(\pi_1=0\)), promenljiva \(j\) se postavlja na \(0\) i porede se karakteri \(t_8=a\) i \(p_0=a\). Ti karakteri su jednaki, pa se sa poređenjem nastavlja dalje i uspešno se pronalazi podniska. Pošto je prazna reč jedini prefiks sufiks cele niske (tj. pošto je \(\pi_6=0\)), naredni karakter bi trebalo porediti sa karakterom \(0\) niske, međutim, jasno je da se došlo do kraja teksta i da neće biti pronađena druga pojavljivanja niske.
Koja je složenost funkcije za pretprocesiranje niske \(p\) dužine \(|p|=m\), prikazane u poglavlju 7.6.1? Unutrašnja petlja smanjuje vrednost promenljive \(j\) bar za 1, jer je \(\pi_j < j\). Petlja se završava najkasnije kada vrednost \(j\) postane \(-1\) (a na početku je \(j\) jednako \(-1\)), te se stoga može smanjiti najviše onoliko puta koliko je prethodno bila povećana naredbom j++. S obzirom na to da se naredba j++ izvršava u spoljašnjoj petlji tačno \(m\) puta, ukupan broj izvršavanja unutrašnje while petlje je ograničen sa \(m\), te je ukupna složenost pretprocesiranja niske \(O(m)\). Potpuno analogno se može zaključiti da je složenost algoritma za traženje niske \(p\) u tekstu \(t\) dužine \(|t|=n\) jednaka \(O(n)\), te je ukupna složenost algoritma KMP \(O(m+n)=O(|p|+|t|)\).
U primeru 7.6.7 smo imali finu ilustraciju složenosti faze pretrage, s obzirom na to da poređenja (uspešna i neuspešna) formiraju “stepenice” koje u najgorem slučaju mogu biti jednako visoke i duge, te je u najgorem slučaju potrebno \(2n\) poređenja prilikom traženja niske u tekstu.
7.6.3 Ispitivanje periodičnosti niske
Pronalaženje najdužih prefiks-sufiksa niski ima i druge primene. Ilustrujmo jednu od njih.
Reč \(w\) je periodična ako postoji neprazna reč \(p = p_1p_2\) i prirodan broj \(n \geq 2\), tako da je \(w = p^np_1\). Na primer, reč \(abacabacabacab\) je periodična jer se u njoj ponavlja reč \(abac\), pri čemu se poslednje ponavljanje ne završava celo već se zaustavlja sa \(ab\), tj. reč je jednaka \((abac)^3ab\). Ako je \(p_1\) prazna niska, tada možemo reći da je niska strogo periodična. Ako bismo dopustili da je \(n=1\), tada bi svaka niska bila periodična.
Ispitivanje periodičnosti niske igra važnu ulogu u različitim domenima. Nekada se koristi kao mera samosličnosti u primenama koje se tiču obrade teksta, analize podataka, računarske biologije i sl.
Problem. Napisati algoritam koji proverava da li je reč \(w\) periodična.
Problem možemo rešiti grubom silom, tako što ćemo za svaku vrednost \(d\) takvu da je \(2d \leq |w|\) proveriti da li je reč periodična, pri čemu je period prefiks reči \(w\) dužine \(d\). Jednostavno se dokazuje da je reč \(w\) periodična sa periodom \(p\) čija je dužina \(d\) ako i samo ako za svako \(i\) za koje je \(0 \leq i\) i \(i + d < |w|\) važi \(w_i = w_{i+d}\). Da bismo proverili da li je niska strogo periodična, dovoljno je dodatno proveriti da li dužina reči \(w\) deljiva brojem \(d\). Problem se onda rešava sa dve ugnežđene linearne pretrage – u spoljnoj proveravamo sve potencijalne vrednosti dužine \(d\), a u unutrašnjoj proveravamo da li postoji vrednost \(i\) takva da je \(w_i \neq w_{i+d}\). Ako u unutrašnjoj petlji utvrdimo da takvo \(i\) ne postoji, tada je niska periodična. Ako pronađemo takvo \(i\), možemo prekinuti unutrašnju petlju (reč nije periodična sa periodom dužine \(d\)) i preći na sledeće \(d\) (za jedan veće). Ako takvo \(d\) ne postoji, tada možemo konstatovati da reč nije periodična.
// provera da li niska stri ima period duzine pbool proveriPeriod(const string& str, int p) {for (int i = 0; i + p < str.size(); i++)if (str[i] != str[i + p])returnfalse;returntrue;}// provera da li je niska periodicna bool periodicna(const string &str) {// proveravamo za svaku mogucu duzinu periodafor (int p = 1; 2 * p <= str.size(); p++) {if (proveriPeriod(str, p))returntrue;returnfalse;}
Složenost najgoreg slučaja ovog algoritma je kvadratna. Zaista, unutrašnja linearna pretraga može u najgorem slučaju zahtevati \(O(|w|)\) iteracija, i ona se ponavlja \(O(|w|)\) puta. Ipak, ako je niska nasumična, realno je očekivati da će se za većinu vrednosti \(d\) veoma brzo ustanovljavati da je \(w_i \neq w_{i+d}\), pa program može raditi dosta brže od najgoreg slučaja.
Efikasnije rešenje se zasniva na narednoj lemi:
Lema 7.6.2.[Karakterizacija periodične niske] Niska \(w\) je periodična ako i samo ako ima prefiks-sufiks \(x\) čija je dužina najmanje polovina niske tj. ako postoje neprazni \(x\), \(s\) i \(t\) takvi da je \(w = xs = tx\) i \(2|x| \geq |w|\) tj. ako je \(\pi_{|w|} \geq |w|/2\).
Primer 7.6.8. Na primer, ako je niska \(abacabacaba\), tada je traženi prefiks-sufiks \(x\) jednak \(abacaba\), sufiks \(s\) jednak je \(caba\), dok je prefiks \(t\) jednak \(abac\). Važi da je \(\pi_{|w|} = \pi_{11} = 7 \geq 11/2\).
Dokaz. Pretpostavimo da je niska \(w\) periodična i pokažimo da ona ima prefiks-sufiks dužine bar polovine niske. Iz uslova da je niska \(w\) periodična sledi da postoji neprazna reč \(p=p_1p_2\) tako da je \(w=p^np_1\), za neko \(n\geq 2\). Tada je \(t=p_1p_2=p\), \(x=p^{n-1}p_1\), dok je \(s=p_2p_1\) (slika 7). Zaista, važi \(xs=p^{n-1}p_1\cdot p_2 p_1=p^n p_1 = w\) i \(tx=p\cdot p^{n-1} p_1=p^n p_1=w\).
Slika 7:\(x\) je prefiks-sufiks periodične niske koji se prostire preko njene sredine.
Pokažimo i da je \(2|x|\geq |w|\). Važi \(|x| = (n-1)|p|+|p_1|\), a iz \(n \geq 2\) sledi \((n-1)\cdot |p| \geq |p|\), pa je \(|x|=(n-1)\cdot|p|+|p_1| \geq |p|+|p_1|=|t|+|p_1|\geq |t|\), te je \(2\cdot |x| \geq |x| + |t| = |w|\).
Dokažimo suprotnu implikaciju. Pretpostavimo da niska \(w\) ima prefiks-sufiks \(x\) dužine bar \(|w|/2\) i da važi \(w=xs=tx\). Pokažimo da je niska \(w\) periodična i da joj je \(t\) period.
Jasno je da su dužine niski \(s\) i \(t\) jednake i neprazne (jer jer svaki prefiks-sufiks \(x\) kraći od cele reči \(w\)).
Neka je \(|w|=q|t|+r, 0\le r<|t|\). Pošto je \(|t| \leq |w|\), važi da je \(q > 0\). Neka je \(w=w_1w_2\ldots w_q z\), gde je \(|w_1|=|w_2|=\ldots=|w_q|=|t|\) i \(|z|=r\). Iz \(w=tx\) sledi \(w_1=t\) i \(w_2\ldots w_qz=x\). Zato je i \(w=xs=w_2\ldots w_q zs\), pa važi redom \(w_2=w_1, w_3=w_2,\ldots,w_{q-1}=w_q\) (slika ??). Iz uslova \(zs=w_qz\) i \(|z| = r < q = |w_q|\), sledi da je \(z\) prefiks niske \(w_q=t\). Odavde dobijamo \(w=t^q z\), pri čemu je \(z\) prefiks neprazne niske \(t\).
Da bismo dokazali da je niska periodična, potrebno je još da dokažemo da je \(q \geq 2\). Iz uslova \(|x|\geq |w|/2\) sledi da je \(|s|=|t|\leq |x|\). Ako bi važilo \(q < 2\), važilo bi \(|w|\leq|t|+r<2|t|\), što zajedno sa pretpostavkom \(|w|\leq 2|x|\) daje \(2|w|<2|x|+2|t|\leq 2|w|\) i dobili bismo kontradikciju.
\(\Box\)
Dakle, rešenje ovog problema se svodi na pronalaženje dužine najdužeg prefiks-sufiksa reči \(w\) (to je vrednost \(\pi_{|w|}\)) i proveru da li važi \(2\pi_{|w|} \geq |w|\). To možemo uraditi već prikazanom funkcijom kmpIzracunajPrefiksSufikse.
bool periodicna(const string& w) {int m = w.size();// racunamo duzinu najduzeg prefiks-sufiksa niske w vector<int> pi = kmpIzracunajPrefiksSufikse(w);// proveravamo duzinu najduzeg prefiks-sufiksa return2 * pi[m] >= m;}
Složenost ovog algoritma jednaka je složenosti algoritma za pretprocesiranje u KMP algoritmu, odnosno jednaka je \(O(|w|)\).
KMP algoritam se može upotrebiti i za određivanje najkraćeg perioda reči \(w\) tj. najkraćeg prefiksa \(p\) reči \(w\) takvog da je \(p=p_1p_2\) i \(w=p^np_1\). Ako reč nije periodična, moguće je da je \(w=pp_1\) ili da je \(w=p\).
Lema 7.6.3.[Najkraća perioda] Dužina najkraćeg perioda niske \(w\) je \(|w| - \pi_{|w|}\).
Dokaz. Ako je \(w=p^np_1\) i \(p=p_1p_2\), tada je \(w=p_1p_2p_1p_2\ldots p_1p_2p_1\), pa je \(p^{n-1}p_1=p_1p_2\ldots p_1p_2p_1\) prefiks-sufiks reči \(w\). Važi i obratno. Ako je \(x\) prefiks-sufiks, tada je \(px=xq\), pa se na isti način kao u lemi 7.6.2 dokazuje da je \(w=p^np_1\) i \(p=p_1p_2\), za odgovarajuće \(n\). Dakle, postoji bijekcija između perioda niske i njenih prefiks-sufiksa.
Ako je \(p\) najkraći prefiks koji zadovoljava uslov periodičnosti, onda je \(|p| \leq |p'|\) za sve druge periode. Ako periodu \(p\) odgovara prefiks-sufiks \(x\), a periodu \(p'\) prefiks-sufiks \(x'\), tada je \(|x'| = |w| - |p'| \leq |w| - |p| = |x|\). Zato najkraćem periodu odgovara najduži prefiks-sufiks niske \(w\). Dakle, dužina \(\pi_{|w|}\) najdužeg prefiks-sufiksa reči \(w\) određuje dužinu \(|w|-\pi_{|w|}\) njenog najkraćeg perioda. \(\Box\)
Da bi reč bila periodična, dužina njenog najkraćeg perioda mora da bude kraća od polovine niske, odnosno mora da važi \(|w| - p_{|w|} \leq |w|/2\), tj. \(2p_{|w|} \geq |w|\), tj. \(p_{|w|} \geq |w|/2\), što je potpuno u skladu sa lemom 7.6.2.
8 Najkraća dopuna do palindroma
Niska \(abaca\) nije palindrom (ne čita se isto sleva i sdesna), ali ako joj na početak dopišemo karaktere \(ac\), dobijamo nisku \(acabaca\) koja jeste palindrom (čita se isto i sleva i sdesna). Napiši program koji za datu nisku određuje dužinu najkraćeg palindroma koji se može dobiti dopisivanjem karaktera s leve strane date niske.
8.1 Opis ulaza
Sa standardnog ulaza se unosi niska sastavljena od \(N\) (\(1\leq N \leq 50000\)) malih slova engleske abecede.
8.2 Opis izlaza
Na standardni izlaz ispisati traženu dužinu najkraće proširene niske koja je palindrom.
8.3 Primer 1
8.3.1 Ulaz
abacba
8.3.2 Izlaz
9
8.4 Primer 2
8.3.1 Ulaz
anavolimilovana
8.3.2 Izlaz
15
8.5 Primer 3
8.3.1 Ulaz
anavolimilovanakapak
8.3.2 Izlaz
25
8.6 Rešenje
Pretpostavimo da se najkraći mogući palindrom može dobiti dopisivanjem niske \(p\) na nisku \(s\) tj. da je \(ps\) najkraći palindrom kome je \(s\) sufiks. Tada je \(ps = s'p'\), gde je \(s'\) niska koja se dobija obrtanjem karaktera niske \(s\), dok je \(p'\) niska koja se dobija obrtanjem karaktera niske \(p\). Dakle, \(s\) se završava sa \(p'\) i postoji neki njen prefiks \(t\) takav da je \(s = tp'\). Zato je \(ptp' = pt'p'\), gde je \(t'\) niska koja se dobija obrtanjem karaktera niske \(t\), pa je \(t=t'\), tj. \(t\) mora biti palindrom. Da bi dužina prefiksa \(p\) bila što manja, dužina palindroma \(t\) mora biti što veća, pa je \(t\) najduži mogući palindrom kojim počinje niska \(s\).
Primer 8.6.1. Na primer, da bismo odredili najduži palindrom kojim se dopunjuje niska \(s = abacba\), primećujemo da je njen najduži palindromski prefiks niska \(t = aba\), odakle sledi \(p' = cba\), pa je \(p = abc\) i rezultujući palindrom je \(ps = abcabacba\).
Ako je \(n_t\) dužina palindroma \(t\), a \(n\) dužina niske \(s\), dužina dela \(p\) jednaka je \(n-n_t\), pa je ukupna dužina traženog palindroma jednaka \((n-n_t) + n = 2n-n_t\).
Palindrom \(t\) možemo odrediti grubom silom, tako što redom proveravamo sve prefikse niske \(s\) i tražimo najduži palindrom među njima.
Zadatak efikasnije možemo rešiti algoritmom KMP. Ako umesto niske \(s\) posmatramo nisku \(ss'\) dobijenu nadovezivanjem niske dobijene obrtanjem redosleda karaktera niske \(s\) na nisku \(s\), najduži palindromski prefiks niske \(s\) je najduži prefiks niske \(ss'\) koji je ujedno njen sufiks i koji ima najviše \(n\) karaktera, gde je \(n\) dužina niske \(s\). Da bi se sprečilo da se prilikom popunjavanja KMP niza uračunaju i oni sufiksi i prefiksi koji sadrže celu polaznu nisku, dovoljno je da se između niski \(s\) i \(s'\) postavi proizvoljni karakter koji one ne sadrže (pošto se niske sastoje samo od malih slova engleske abecede, možemo, na primer, upotrebiti karakter .). Kada izgradimo nisku \(s.s'\), tada popunjavamo KMP niz \(\pi\) i njegov poslednji element predstavlja dužinu najdužeg palindromskog prefiksa. Složenost ovog algoritma je \(O(|s|)\).
// izracunava duzinu najduzeg prefiksa niske s koji je palindromint duzinaNajduzegPalindromskogPrefiksa(const string& s) { string sObratno(s.rbegin(), s.rend()); string str = s + "." + sObratno; vector<int> kmp = kmpIzracunajPrefiksSufikse(str);return kmp[kmp.size() - 1];}// odredjuje duzinu najkraćeg palindroma koji se može dobiti// dopisivanje slova na pocetak niske sint najkraciPalindrom(const string& s) {// s razlazemo na prefiks + sufiks tako da je prefiks sto duzi// palindrom. Tada je trazeni palindrom dobijen sa sto manje// dopisivanja slova na pocetak jednak:// obrni(sufiks) + prefiks + sufiksint duzinaPrefiksa = duzinaNajduzegPalindromskogPrefiksa(s);int duzinaSufiksa = s.size() - duzinaPrefiksa;int duzinaNajkracegPalindroma = duzinaSufiksa + duzinaPrefiksa + duzinaSufiksa;return duzinaNajkracegPalindroma;}
#include <iostream>#include <vector>#include <string>#include <algorithm>usingnamespace std;vector<int> kmpIzracunajPrefiksSufikse(const string& str) { vector<int> kmp(str.size() + 1, 0); kmp[0] = -1;for (int i = 0; i < str.size(); i++) {int k = i;while (k > 0 && str[i] != str[kmp[k]]) k = kmp[k]; kmp[i + 1] = kmp[k] + 1; }return kmp;}// izracunava duzinu najduzeg prefiksa niske s koji je palindromint duzinaNajduzegPalindromskogPrefiksa(const string& s) { string sObratno(s.rbegin(), s.rend()); string str = s + "." + sObratno; vector<int> kmp = kmpIzracunajPrefiksSufikse(str);return kmp[kmp.size() - 1];}// odredjuje duzinu najkraćeg palindroma koji se može dobiti// dopisivanje slova na pocetak niske sint najkraciPalindrom(const string& s) {// s razlazemo na prefiks + sufiks tako da je prefiks sto duzi// palindrom. Tada je trazeni palindrom dobijen sa sto manje// dopisivanja slova na pocetak jednak:// obrni(sufiks) + prefiks + sufiksint duzinaPrefiksa = duzinaNajduzegPalindromskogPrefiksa(s);int duzinaSufiksa = s.size() - duzinaPrefiksa;int duzinaNajkracegPalindroma = duzinaSufiksa + duzinaPrefiksa + duzinaSufiksa;return duzinaNajkracegPalindroma;}int main() { string s; cin >> s; cout << najkraciPalindrom(s) << endl;return0;}
9 Domine
Domine se slažu jedna uz drugu, tako što se polja na dominama postavljenim jednu uz drugu moraju poklapati. Domine obično imaju samo dva polja, međutim, naše su domine specijalne i imaju više različitih polja (označenih slovima). Ako sve domine koje slažemo imaju istu šaru, napiši program koji određuje kako je domine moguće složiti tako da zauzmu što manje prostora po dužini (svaka naredna domina mora biti smaknuta bar za jedno polje). Na primer, ako na dominama piše ababcabab, najmanje prostora zauzimaju ako se slože na sledeći način:
ababcabab
ababcabab
ababcabab
8.1 Opis ulaza
Prvi red standardnog ulaza sadrži nisku malih slova engleske abecede koje predstavljaju šare na dominama. Dužina niske je između \(2\) i \(10^5\) karaktera. U narednom redu se nalazi ceo broj \(n\)\((1 \leq n \leq 5\cdot 10^4)\) koji predstavlja broj domina.
8.2 Opis izlaza
Na standardni izlaz ispisati ceo broj koji predstavlja ukupnu dužinu složenih domina.
8.3 Primer 1
8.3.1 Ulaz
ababcabab
3
8.3.2 Izlaz
19
8.4 Primer 2
8.3.1 Ulaz
abc
5
8.3.2 Izlaz
15
8.5 Primer 3
8.3.1 Ulaz
aa
10
8.3.2 Izlaz
11
8.6 Rešenje
Prilikom slaganja domina potrebno je da se poklope neki pravi prefiks i pravi sufiks teksta na dominama. Da bi domine zauzimale što manje prostora, potrebno je da preklapanje bude što duže. Dakle, potrebno je pronaći dužinu \(k\) najdužeg prefiks-sufiks niske \(s\). Ukupna dužina domina je tada \(k + n\cdot (|s| - k)\). Naime, nakon prve domine dužine \(|s|\), svaka naredna domina doda još \(|s|-k\) karaktera.