U nastavku ćemo razmotriti još jednu strukturu podataka koja omogućava efikasno računanje statistika nad segmentima niza i ažuriranje pojedinačnih elemenata: to su Fenvikova drveta (engl. Fenwick tree), tj. binarno indeksirana drveta (engl. binary indexed tree, BIT) koja se malo jednostavnije implementiraju od segmentnih drveta, koriste malo manje memorije i mogu da budu za konstantni faktor brža od njih (iako je složenost operacija asimptotski jednaka). S druge strane, za razliku od segmentnih drveta, koja su pogodna za različite operacije, Fenvikova drveta su specijalizovana samo za asocijativne operacije koje imaju odgovarajuće inverzne (suprotne) operacije (npr. zbir ili proizvod elemenata segmenata se može nalaziti uz pomoć Fenvikovih drveta, jer sabiranju odgovara oduzimanje, a množenju deljenje, ali ne i minimum, najveći zajednički delilac i slično). Potrebu da za razmatranu operaciju postoji inverzna operacija ćemo detaljnije diskutovati kada budemo govorili o realizaciji samih operacija. Segmentna drveta mogu da urade sve što i Fenvikova, dok obratno ne važi.
Slično kao što je slučaj kod segmentnih drveta, iako se naziva drvetom, Fenvikovo drvo zapravo predstavlja niz vrednosti zbirova nekih pametno izabranih segmenata originalnog niza \(a\). Izbor segmenata je u tesnoj vezi sa binarnom reprezentacijom indeksa. Ključna Fenvikova ideja je sledeća:
Kao što se svaki prirodan broj može dobiti sabiranjem nekih stepena dvojke koji su određeni njegovom binarnom reprezentacijom (svaka jedinica i njen položaj u binarnoj reprezentaciji određuje neki stepen dvojke), tako se i svaki prefiks niza može dobiti nadovezivanjem nekih segmenata koji su određeni binarnom reprezentacijom granice tog segmenta (svaka jedinica i njen položaj u binarnoj reprezentaciji određuje jedan takav segment).
Ponovo ćemo, jednostavnosti radi, pretpostaviti da se vrednosti smeštaju od pozicije \(1\) (vrednost na poziciji \(0\) je irelevantna) i to i u polaznom nizu \(a\), i u nizu u kom se smešta Fenvikovo drvo. Prilagođavanje koda situaciji u kojoj su u polaznom nizu elementi smešteni od pozicije nula veoma je jednostavno, samo je na početku svake funkcije koja radi sa drvetom indeks polaznog niza potrebno uvećati za jedan pre dalje obrade. Dakle, ako je polazni niz dužine \(n\), elementi drveta se smeštaju u poseban niz na pozicije \([1, n]\).
Definicija Fenvikovog drveta je sledeća:
U drvetu se na poziciji \(k\) čuva zbir vrednosti polaznog niza sa pozicija iz intervala \((f(k), k]\), gde je \(f(k)\) broj koji se dobija od broja \(k\) tako što se u binarnom zapisu broja \(k\) prva jedinica zdesna zameni nulom.
Primer 1.4.8.
U Fenvikovom drvetu se na poziciji \(k=21\) zapisuje zbir elemenata polaznog niza sa pozicija iz intervala \((20, 21]\). Naime, broj \(21\) se binarno zapisuje kao \((10101)_2\) i zamenom prve jedinice zdesna nulom u njegovom binarnom zapisu dobija se binarni zapis \((10100)_2\), tj. broj \(20\) (važi \(f(21) = 20\)).
Na poziciji \(20\) u Fenvikovom drvetu nalazi se zbir elemenata polaznog niza sa pozicija iz intervala \((16, 20]\), jer se brisanjem krajnje desne jedinice iz njegovog binarnog zapisa \((10100)_2\) dobija binarni zapis \((10000)_2\) tj. broj \(16\) (važi \(f(20) = 16\)).
Na poziciji \(16\) u Fenvikovom drvetu čuva se zbir elemenata polaznog niza sa pozicija iz intervala \((0, 16]\), jer se brisanjem kranje desne jedinice iz binarnog zapisa broja \(16\) dobija \(0\) (važi \(f(16) = 0\)).
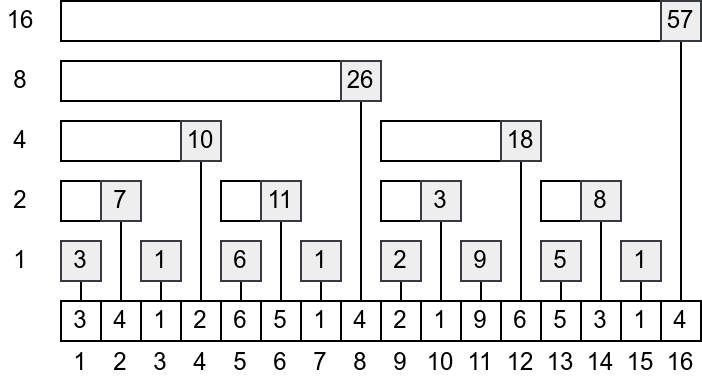
Na slici 1 je za niz dužine \(16\) prikazano koji se zbirovi segmenata polaznog niza čuvaju na svakoj od pozicija u Fenvikovom drvetu. Primetimo da neparne pozicije odgovaraju segmentima dužine 1, a da za stepene broja 2 segmenti predstavljaju prefikse polaznog niza do te pozicije.
Primer 1.4.9. Razmotrimo niz \(a\) sa vrednostima \(3, 4, 1, 2, 6, 5, 1, 4\). Odgovarajuće Fenvikovo drvo čuva sledeće vrednosti:
| \(0\) | \(1\) | \(2\) | \(3\) | \(4\) | \(5\) | \(6\) | \(7\) | \(8\) | \(k\) |
|---|---|---|---|---|---|---|---|---|---|
| \(0001\) | \(0010\) | \(0011\) | \(0100\) | \(0101\) | \(0110\) | \(0111\) | \(1000\) | \(k\) binarno | |
| \(0000\) | \(0000\) | \(0010\) | \(0000\) | \(0100\) | \(0100\) | \(0110\) | \(0000\) | \(f(k)\) binarno | |
| \(0\) | \(0\) | \(2\) | \(0\) | \(4\) | \(4\) | \(6\) | \(0\) | \(f(k)\) | |
| \((0, 1]\) | \((0, 2]\) | \((2, 3]\) | \((0, 4]\) | \((4, 5]\) | \((4, 6]\) | \((6, 7]\) | \((0, 8]\) | interval | |
| \(3\) | \(4\) | \(1\) | \(2\) | \(6\) | \(5\) | \(1\) | \(4\) | niz \(a\) | |
| \(3\) | \(7\) | \(1\) | \(10\) | \(6\) | \(11\) | \(1\) | \(26\) | Fenvikovo drvo |
Pomoću narednog apleta možete proveriti svoje razumevanje organizacije podataka u Fenvikovom drvetu.
Možete probati i da popunite elemente Fenvikovog drveta sabirajući odgovarajuće segmente.
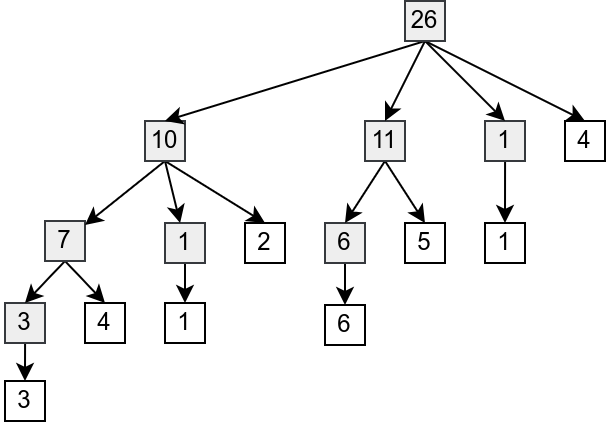
Na slici 2 prikazana je zavisnost zbirova segmenata od njihovih podsegmenata, odakle se jasno vidi da je zaista u pitanju drvolika struktura (otuda i potiče naziv Fenvikovo drvo). U listovima ove strukture nalaze se elementi polaznog niza, dok se u unutrašnjim čvorovima nalaze elementi Fenvikovog drveta.
Implementacija raznih operacija nad Fenvikovim drvetom je veoma jednostavna, ako se zna način da se iz binarnog zapisa broja ukloni prva jedinica zdesna tj. da se za dati broj \(k\) izračuna vrednost \(f(k)\). Označimo sa \(b(k)\) binarni broj koji sadrži samo jednu jedinicu i to na mestu poslednje jedinice u binarnom zapisu broja \(k\). Važi da je \(f(k) = k - b(k)\).
Pod pretpostavkom da su brojevi zapisani u potpunom komplementu, vrednost \(b(k)\) se može izračunati izrazom k & -k. Oduzimanjem te vrednosti od broja \(k\) tj. izrazom k - (k & -k) dobijamo efekat brisanja poslednje jedinice u binarnom zapisu broja \(k\) i to predstavlja implementaciju funkcije \(f\).
Primer 1.4.10. Broju \(k=20\) odgovara binarni zapis \((00010100)_2\), a broju \(-k\) binarni zapis \((11101100)_2\), te je k & -k jednako \((00000100)_2\) i predstavlja broj koji sadrži samo jednu jedinicu i to na mestu poslednje jedinice u zapisu broja \(k\). Oduzimanjem ove vrednosti od broja \(k\) dobijamo broj \(16\) kome odgovara binarna reprezentacija \((00010000)_2\).
Dokažimo ispravnost operacije uklanjanje poslednje jedinice iz binarnog zapisa broja.
Lema 1.4.2. [Računanje broja \(f(k)\)] Za bilo koji neoznačeni binarni broj \(k\) veći od nule izrazom k & -k se izračunava broj \(b(k)\) tj. broj koji se sastoji samo od poslednje jedinice u binarnom zapisu broja \(k\), a izrazom k - (k & -k) se izračunava broj \(f(k)\) dobijen od broja \(k\) brisanjem poslednje jedinice iz njegovog binarnog zapisa.
Dokaz. Potpuni komplement broja \(k\) se dobija tako što se broju \(k\) invertuju svi bitovi i dobijeni rezultat se uveća za 1. Neka broj \(k\) ima svoju poslednju jedinicu na poziciji \(p\) (ako ima bitova desno od pozicije \(p\), oni su svi nule). Kada se negiraju bitovi dobija se broj koji ima nulu na poziciji \(p\) iza koje do kraja slede jedinice (ako ih uopšte ima). Sabiranjem sa 1 dobija se broj koji na poziciji \(p\) ima 1 iza čega se nalaze nule. Dakle, levo od pozicije \(p\) bitovi broja \(k\) i \(-k\) su suprotni, na poziciji \(p\) oba imaju jedinice, a desno od pozicije \(p\) oba imaju nule. Bitovska konjunkcija brojeva \(k\) i \(-k\) daje rezultat \(b(k)\) koji ima samo jednu jedinicu i to na poziciji \(p\) (to je jedino mesto gde i \(k\) i \(-k\) imaju vrednost 1). \(\Box\)
Drugi način da se izračuna vrednost \(f(k)\) jeste računanjem vrednosti izraza k & (k-1). Ispravnost ovog izraza se takođe može jednostavno dokazati. Naime, broj k-1 ima sve iste bitove od krajnjeg levog do pozicije poslednjog postavljenog bita u broju \(k\), a sve invertovane bitove posle krajnjeg desnog postavljenog bita u broju \(k\).
Primer 1.4.11. Binarni zapis broja \(k=20\) je \((00010100)_2\), a broja \(k-1=19\) je \((00010011)_2\) i izrazu k & (k-1) odgovara binarni zapis \((00010000)_2\).
Ipak, izraz k - (k & -k) se češće koristi, zbog sličnosti sa izrazom k + (k & -k), koji se koristi prilikom izračunavanja funkcije \(g\) koja je definisana u poglavlju 1.4.2.2.2 posvećenom ažuriranju vrednosti elemenata niza.
Zbir elemenata u bilo kom prefiksu polaznog niza može da se dobije kao zbir nekoliko elemenata zapisanih u Fenvikovom drvetu.
Primer 1.4.12. Interval pozicija \((0, 21]\) tj. prefiks niza do pozicije \(21\) se dobija nadovezivanjem intervala \((0, 16]\), \((16, 20]\) i \((20, 21]\).
Ove intervale je jednostavno odrediti. Na poziciji \(k\) se nalazi zbir elemenata sa pozicija iz intervala \((f(k), k]\), na poziciji \(f(k)\) zbir elemenata sa pozicija iz intervala \((f(f(k)), f(k)]\), itd. Postupak se nastavlja sabirajući elemente sa pozicija \(k\), \(f(k)\), \(f(f(k))\), \(f(f(f(k)))\) itd., sve dok se ne dođe do pozicije nula.
Pomoću narednog apleta možete proveriti svoje razumevanje izračunavanja zbirova prefiksa korišćenjem Fenvikovog drveta.
Broj elemenata Fenvikovog drveta čijim se sabiranjem dobija zbir prefiksa polaznog niza je \(O(\log{n})\). Naime, u svakom koraku se broj jedinica u binarnom zapisu tekućeg indeksa smanjuje, a broj \(n\) se binarno zapisuje sa najviše \(O(\log{n})\) binarnih jedinica.
Zbir elemenata prefiksa na pozicijama iz intervala \((0, k]\) polaznog niza \(a\) smeštenog u Fenvikovo drvo drvo možemo onda izračunati narednom funkcijom.
// na osnovu Fenvikovog drveta smeštenog u niz drvo
// izračunava zbir prefiksa (0, k] polaznog niza
int zbirPrefiksa(const vector<int>& drvo, int k) {
int zbir = 0;
while (k > 0) {
zbir += drvo[k];
k -= k & -k; // k = f(k)
}
}Kada umemo da izračunamo zbirove prefiksa polaznog niza, zbir proizvoljnog segmenta određenog pozicijama \([a, b]\) polaznog niza možemo izračunati kao razliku zbira prefiksa određenog pozicijama \((0, b]\) i zbira prefiksa određenog pozicijama \((0, a-1]\). Pošto se oba prefiksa računaju u vremenu \(O(\log{n})\), i zbir svakog segmenta možemo izračunati u vremenu \(O(\log{n})\). Istaknimo na ovom mestu da je zbog ove operacije važno da asocijativna operacija koja se koristi u Fenvikovom drvetu ima inverznu operaciju (u ovom slučaju, pošto se radi o operaciji sabiranja, da bismo mogli da oduzimanjem dve vrednosti prefiksa dobijemo zbir proizvoljnog segmenta1).
Ideju računanja zbira elemenata proizvoljnog segmenta kao razlike dva zbira prefiksa smo videli već ranije, kada smo u te svrhe održavali niz svih zbirova prefiksa. Osnovna prednost Fenvikovih drveta u odnosu na niz svih zbirova prefiksa je to što se mogu efikasno ažurirati. Naime, ažuriranje jednog elementa polaznog niza može rezultovati izmenom vrednosti velikog broja prefiksnih zbirova, naročito ako je element koji menjamo blizu početka niza (u najgorem slučaju broj zbirova koje je potrebno ažurirati je \(O(n)\)). Stoga je operacija ažuriranja elementa kada se koriste prefiksni zbirovi u najgorem slučaju složenosti \(O(n)\).
Razmotrimo funkciju koja ažurira Fenvikovo drvo nakon uvećanja elementa u polaznom nizu na poziciji \(k\) za vrednost \(x\). Tada je za \(x\) potrebno uvećati sve one zbirove u drvetu u kojima se kao sabirak javlja i element na poziciji \(k\). Potrebno je ažurirati sve one pozicije \(m\) čiji pridruženi segment sadrži vrednost \(k\), tj. sve one pozicije \(m\) takve da je \(k \in (f(m), m]\), tj. pozicije \(m\) za koje važi
\[f(m) < k \leq m\](1)
Te pozicije se izračunavaju veoma jednostavno krenuvši od polazne pozicije \(k\), slično kao u prethodnoj funkciji, s tim što se umesto da se od broja \(k\) oduzima vrednost \(b(k)\), broj \(k\) uvećava za vrednost izraza \(b(k)\). Obeležimo sa \(g(k)\) broj \(k+b(k)\), koji se dobija od broja \(k\) tako što se \(k\) sabere sa brojem koji ima samo jednu jedinicu u svom binarnom zapisu i to na poziciji na kojoj se nalazi poslednja jedinica u binarnom zapisu broja \(k\). U implementaciji se broj \(g(k)\) lako može izračunati po formuli k + (k & -k).
Primer 1.4.13. Za broj \(k = (101100)_2\) važi \(g(k) = (101100)_2 + (100)_2 = (110000)_2\).
Dokazaćemo da je potrebno i dovoljno ažurirati vrednosti na pozicijama \(k\), \(g(k)\), \(g(g(k))\) itd., sve dok se ne dođe do pozicije koja je strogo veća od dužine niza \(n\).
Primer 1.4.14. Ako bi se u prethodnom primeru element na poziciji \(3\) u polaznom nizu uvećao za vrednost \(4\), bilo bi potrebno povećati za \(4\) vrednosti elemenata Fenvikovog drveta na pozicijama \(3\), \(4\) i \(8\). Do niza ovih pozicija bismo mogli da dođemo na sledeći način.
Prva pozicija je broj \(k=3\).
Narednu poziciju \(g(3)\) dobijamo tako što binarnom zapisu broja \(3\) koji iznosi \((0011)_2\), dodajemo broj \(1\) (broj \(b(3)\) koji sadrži tačno jednu jedinicu na poziciji poslednje jedinice u binarnom zapisu datog broja) i dobijamo binarni zapis \(g(3) = (0100)_2\) koji odgovara broju \(4\).
Narednu poziciju \(g(g(3)) = g(4)\) bismo dobili tako što bismo vrednost 4 sabrali sa \((0100)_2\) (brojem \(b(4)\) koji sadrži tačno jednu jedinicu u svom binarnom zapisu i to na poziciji poslednje jedinice), čime bismo dobili \(g(4) = (1000)_2\) (binarni zapis broja \(8\)). Ovde se procedura završava pošto smo stigli do poslednjeg elementa u Fenvikovom drvetu.
S obzirom na to da se broj \(n\) binarno zapisuje sa \(O(\log{n})\) bitova i da se u svakom koraku broj krajnjih nula u zapisu broja povećava (iako u svakom koraku vrednost broja raste), ukupan broj koraka je jednak \(O(\log n)\). Dakle, broj elemenata Fenvikovog drveta čije je vrednosti potrebno izmeniti iznosi \(O(\log n)\).
Pomoću narednog apleta možete proveriti svoje razumevanje ažuriranja Fenvikovog drveta.
// ažurira Fenvikovo drvo smešteno u niz drvo nakon što se
// u originalnom nizu element na poziciji k uveća za x
void uvecaj(vector<int>& drvo, int n, int k, int x) {
while (k <= n) {
drvo[k] += x;
k += k & -k;
}
}Dokažimo korektnost opisanog postupka. Krenimo od naredne leme.
Lema 1.4.3. Za svako \(x\) između \(1\) i \(n\), najmanji broj \(m\) koji zadovoljava uslov \(f(m) < x < m\) je \(g(x)\).
Dokaz. Pokažimo najpre da \(g(x)\) zadovoljava ovaj uslov. Očigledno važi \(x < g(x)\). Pošto \(g(x)\) ima sve nule od pozicije poslednje jedinice u binarnom zapisu broja \(x\) (uključujući i nju), pa do kraja, brisanjem njegove poslednje jedinice tj. izračunavanjem vrednosti \(f(g(x))\) se sigurno dobija broj koji je strogo manji od \(x\).
Pokažimo sada da je \(g(x)\) najmanji broj strogo veći od \(x\) koji zadovoljava dati uslov, odnosno da nijedan broj \(m\) između \(x\) i \(g(x)\) ne može da zadovolji uslov \(f(m) < x\). Naime, svi brojevi iz intervala \((x, g(x))\) se poklapaju sa brojem \(x\) na svim pozicijama pre krajnjih nula, a na pozicijama krajnjih nula broja \(x\) imaju bar neku jedinicu, čijim se brisanjem dobija broj koji je veći ili jednak \(x\). \(\Box\)
Primer 1.4.15. U prethodno razmatranom primeru za \(k = (101100)_2\), kao što smo već videli važi \(g(k) = (110000)_2\) i jedini brojevi između \(k\) i \(g(k)\) su \((101101)_2\), \((101110)_2\) i \((101111)_2\). Brisanjem poslednje jedinice u binarnom zapisu ovih brojeva dobijaju se redom brojevi \((101100)_2\), \((101100)_2\) i \((101110)_2\) i svi oni su veći ili jednaki od \(k\).
Dokažimo i drugu pomoćnu lemu.
Lema 1.4.4. Za svako \(1 \leq x \leq n\) važi \(f(g(x)) \leq f(x)\).
Dokaz. Važi da je \(f(g(x)) = g(x) - b(g(x)) = x + b(x) - b(g(x))\) i \(f(x) = x - b(x)\). Zato je dovoljno dokazati da je \(x + b(x) - b(g(x)) \leq x - b(x)\) tj. da je \(2b(x) \leq b(g(x))\). Neka \(b(x)\) ima jedinicu na poziciji \(p\). Broj \(2b(x)\) ima jedinicu na poziciji \(p+1\) (brojano zdesna). Broj \(g(x)\) sigurno ima sve nule od pozicije \(p\) do kraja, pa se njegova poslednja jedinica nalazi ili na poziciji \(p+1\) ili levo od nje, na osnovu čega lako sledi da je on veći ili jednak od \(2b(x)\), koji ima jedinicu na poziciji \(p+1\). Ovim je tvrđenje dokazano. \(\Box\)
Dokažimo sada i glavno tvrđenje.
Teorema 1.4.1. Niz vrednosti \(k\), \(g(k)\), \(g(g(k))\), itd. koje su manje ili jednake od dužine niza \(n\) određuje sve vrednosti \(m\) takve da važi \(k \in (f(m), m]\) tj. takve da važi jednakost (1).
Dokaz. Jednakost (1) ne može da važi za brojeve \(m < k\), a sigurno važi za broj \(m = k\), jer je \(f(k) < k\) kada je \(k > 0\) (a mi pretpostavljamo da je \(1 \leq k \leq n\)). Dakle prva pozicija u drvetu koju treba ažurirati je pozicija \(k\).
Za sve brojeve \(m > k\), sigurno važi desna nejednakost i jedino je potrebno utvrditi da li važi leva tj. da li je \(f(m) < k\). Na osnovu primene leme 1.4.3 na broj \(k\) znamo da je \(g(k)\) najmanji broj \(m\) strogo veći od \(k\) za koji važi \(f(m) < k\).
Dalje, na osnovu primene leme 1.4.3 na broj \(g(k)\) znamo da je najmanji broj veći od \(g(k)\) za koji važi \(f(m) < g(k)\) broj \(g(g(k))\). On zadovoljava uslov (1). Zaista, važi \(k < g(k) < g(g(k))\). Na osnovu leme 1.4.4 primenjene na \(g(k)\) važi je \(f(g(g(k))) \leq f(g(k)) < k\). Broj \(g(g(k))\) je i najmanji broj koji veći od \(g(k)\) koji zadovoljava uslov (1). Ako bi neki broj \(m\) između \(g(k)\) i \(g(g(k))\) zadovoljio uslov (1), važilo bi da je \(f(m) < k < g(k)\), što je u suprotnosti sa time da je \(g(g(k))\) najmanji broj \(m\) veći od \(g(k)\) takav da je \(f(m) < g(k)\).
Dokaz se dalje nastavlja i završava po potpuno istom principu (što se može formalizovati indukcijom). \(\Box\)
Prethodna teorema garantuje da su jedine pozicije koje treba ažurirati u drvetu prilikom ažuriranja elementa na poziciji \(k\) u polaznom nizu upravo pozicije iz serije \(k\), \(g(k)\), \(g(g(k))\), itd., sve dok su one manje ili jednake \(n\), pa su prethodni postupak i njegova implementacija korektni.
Ostaje još pitanje kako inicijalno formirati Fenvikovo drvo. Formiranje se može svesti na to da se kreira drvo popunjeno samo nulama, a da se zatim uvećava vrednost jednog po jednog elementa niza prethodnom funkcijom.
// na osnovu niza a u kom su elementi smešteni
// na pozicijama iz segmenta [1, n] formira Fenvikovo drvo
// i smešta ga u niz drvo (na pozicije iz segmenta [1, n])
vector<int> formirajDrvo(int n, const vector<int>& a) {
vector<int> drvo(n+1);
fill_n(drvo + 1, n, 0);
for (int k = 1; k <= n; k++)
uvecaj(drvo, n, k, a[k]);
return drvo;
}Primer 1.4.16. Razmotrimo problem formiranja Fenvikovog drveta za niz vrednosti \(3, 1, 9, 4, 6, 6, 2, 7\). Krenuvši od niza koji sadrži samo nule, uvećavamo jedan po jedan element niza.

Naredni aplet ilustruje postupak kreiranja Fenvikovog drveta na osnovu niza.
Ova implementacija \(n\) puta poziva funkciju uvecaj koja je složenosti \(O(\log n)\), te je ukupna složenost ovog algoritma \(O(n\log n)\). Međutim, pokazuje se da možemo i bolje od ovog. Naime, svaki element Fenvikovog drveta sadrži zbir elemenata nekog segmenta polaznog niza, pa za izračunavanje elemenata Fenvikovog drveta možemo iskoristiti zbirove prefiksa. Naime, element na poziciji \(k\) u Fenvikovom drvetu dobijamo kao razliku zbira prefiksa \((0,k]\) i zbira prefiksa \((0,f(k)]\), ako je \(f(k)>0\), dok ako je \(f(k)=0\) element na poziciji \(k\) biće jednak baš zbiru prefiksa \((0,k]\).
vector<int> formirajDrvoPrefiksneSume(int n, const vector<int>& a) {
vector<int> drvo(n+1);
vector<int> sume_prefiksa(n+1,0);
sume_prefiksa[1] = a[1];
for (int k = 2; k <= n; k++)
sume_prefiksa[k] = sume_prefiksa[k-1] + a[k];
fill_n(drvo + 1, n, 0);
for (int k = 1; k <= n; k++) {
// racunamo f(k)
int f_k = k - (k & -k);
// od sume prefiksa do k oduzimamo sumu prefiksa do f(k)
// ako je f(k)=0, onda ne vrsimo oduzimanje
drvo[k] = sume_prefiksa[k] - (f_k > 0 ? sume_prefiksa[f_k] : 0);
}
return drvo;
}Izračunavanje zbirova svih prefiksa polaznog niza je vremenske složenosti \(O(n)\), ali se nakon toga elementi Fenvikovog drveta računaju u vremenu \(O(1)\), te je ukupna vremenska složenost ovog pristupa \(O(n)\). Ova implementacija pak zahteva dodatni memorijski prostor veličine \(O(n)\) za smeštanje prefiksnih zbirova.
Primetimo da su za izračunavanje \(k\)-tog elementa Fenvikovog drveta potrebni samo elementi niza prefiksnih zbirova na pozicijama \(j\leq k\). Ovo opažanje omogućava da koristimo samo jedan niz koji ćemo inicijalizovati na niz prefiksnih zbirova, a zatim počev od poslednjeg elementa niza idući ka prvom elementu menjati element po element sa prefiksnog zbira na element Fenvikovog drveta.
vector<int> formirajDrvoPrefiksneSumeOpt(int n, const vector<int>& a) {
vector<int> drvo(n+1);
fill_n(drvo+1, n, 0);
drvo[1] = a[1];
for (int k = 2; k <= n; k++)
drvo[k] = drvo[k-1] + a[k];
for (int k = n; k >= 1; k--){
int f_k = k - (k & -k);
if (f_k > 0) drvo[k] -= drvo[f_k];
}
return drvo;
}Ova implementacija algoritma za formiranje Fenvikovog drveta je vremenske složenosti \(O(n)\), a dodatne prostorne složenosti \(O(1)\).
Obratimo pažnju da ako se Fenvikovim drvetom računaju proizvodi segmenata, elementi drveta moraju biti različiti od nule, zbog operacije deljenja.↩︎